[three]Bean
Listing all fedmsg topics
Sep 09, 2016 | categories: fedmsg, fedora View CommentsRecently, over in a pull request review, we found the need to list all of the existing fedmsg topics (to see if some code we were writing would or wouldn't stumble on any of them).
Way back when, we added a feature to datagrepper that would let you list all of the unique topics, but it never worked and was eventually removed.
Here's the next best thing:
#!/usr/bin/env python from fedmsg_meta_fedora_infrastructure import ( tests, doc_utilities, ) from fedmsg.tests.test_meta import Unspecified classes = doc_utilities.load_classes(tests) classes = [cls for cls in classes if hasattr(cls.context, 'msg')] topics = [] for cls in classes: if not cls.context.msg is Unspecified: topics.append(cls.context.msg['topic'] .replace('.stg.', '.prod.') .replace('.dev.', '.prod.')) # Unique and sort topics = sorted(list(set(topics))) import pprint pprint.pprint(topics)
Enjoy!
Speeding up that nose test suite.
Jun 23, 2015 | categories: python, fedmsg, fedora, nose View CommentsShort post: I just discovered the --with-prof option to the nosetests command. It profiles your test suite by using the hotshot module from the Python standard library and it found a huge sore spot in my most frequently run suite. In this pull request we got the fedmsg_meta running 31x faster.
Compare before:
(fedmsg_meta)❯ time $(which nosetests) -x Ran 3822 tests in 270.822s OK (SKIP=1638) ---------------------------------------------------------------------- Success! $(which nosetests) -x 267.30s user 1.32s system 98% cpu 4:33.53 total
And after:
(fedmsg_meta)❯ time $(which nosetests) -x Ran 3822 tests in 5.982s OK (SKIP=1638) ---------------------------------------------------------------------- Success! $(which nosetests) -x 3.87s user 0.71s system 52% cpu 8.700 total
That test suite used to take forever. It's the whole reason I wrote nose-audio in the first place!
Karma Cookies, and how to give them
Mar 19, 2015 | categories: fedmsg, fedora, badges View CommentsIt took a while to get all the ingredients together, but we baked up a delicious batch of new Fedora Badges and they're fresh out of the oven.
To quote mizmo from the original ticket:
So here's the idea. The FPL has the FPL blessing, right? But, someone did something really helpful and awesome for me today, with no expectation of getting anything in return. This person really made my life easier. And I really wish I could give him something as a token of my appreciation. So my thought here - maybe everyone in the Fedora project gets an amount of cookie badges that they can hand out as thank yous to others in the project as they're getting things done and helping each other out. You can't award one to yourself, only others. Maybe you get one cookie for every 5 badges you have earned, so folks get a number of cookies proportional to their achievements in the system, and if they run out they can replenish their cookies by earning more badges.
The excellent riecatnor got to work and whipped up some treats:

The last missing piece was a new plugin for zodbot that listens for USERNAME++ in IRC and publishes a new karma message to Fedora Infrastructure's message bus.
That's all done and in place now. You can grant someone karma like this:
| threebean | riecatnor++
And check to see how much karma a given user has like this:
| threebean │ .karma riecatnor | zodbot │ threebean: Karma for riecatnor has been increased 1 times
Lastly, there are a handful of restrictions on it. You can only give karma to a particular individual once (although you have an unlimited supply of points to give to the entire Fedora community):
| threebean │ riecatnor++ | zodbot │ threebean: You have already given 1 karma to riecatnor
You can't give yourself karma:
| threebean │ threebean++ | zodbot │ threebean: You may not modify your own karma.
You can only give karma to fas users, and you can only give karma if you are a fas user (your irc nick must match your fas username or you must have your ircnick listed in FAS.
There's code in the plugin to allow negative karma, i.e. threebean--, but we have that disabled. Best to stay positive! ;)
Enjoy! As always, if you have questions about this stuff, please do jump into #fedora-apps on freenode and ask away!

Revisiting Datagrepper Performance
Feb 27, 2015 | categories: fedmsg, datanommer, fedora, datagrepper, postgres View CommentsIn Fedora Infrastructure, we run a service somewhat-hilariously called datagrepper which lets you make queries over HTTP about the history of our message bus. (The service that feeds the database is called datanommer.) We recently crossed the mark of 20 million messages in the store, and the thing still works but it has become noticeably slower over time. This affects other dependent services:
- The releng dashboard and others make HTTP queries to datagrepper.
- The fedora-packages app waits on datagrepper results to present brief histories of packages.
- The Fedora Badges backend queries the db directly to figure out if it should award badges or not.
- The notifications frontend queries the db to try an display what messages in the past would have matched a hypothetical set of rules.
I've written about this chokepoint before, but haven't had time to really do anything about it... until this week!
Measuring how bad it is
First, some stats -- I wrote this benchmarking script to try a handful of different queries on the service and report some average response times:
#!/usr/bin/env python import requests import itertools import time import sys url = 'https://apps.fedoraproject.org/datagrepper/raw/' attempts = 8 possible_arguments = [ ('delta', 86400), ('user', 'ralph'), ('category', 'buildsys'), ('topic', 'org.fedoraproject.prod.buildsys.build.state.change'), ('not_package', 'bugwarrior'), ] result_map = {} for left, right in itertools.product(possible_arguments, possible_arguments): if left is right: continue key = hash(str(list(sorted(set(left + right))))) if key in result_map: continue results = [] params = dict([left, right]) for attempt in range(attempts): start = time.time() r = requests.get(url, params=params) assert(r.status_code == 200) results.append(time.time() - start) # Throw away the max and the min (outliers) results.remove(min(results)) results.remove(min(results)) results.remove(max(results)) results.remove(max(results)) average = sum(results) / len(results) result_map[key] = average print "%0.4f %r" % (average, str(params)) sys.stdout.flush()
The results get printed out in two columns.
- The leftmost column is the average number of seconds it takes to make a query (we try 8 times, throw away the shortest and the longest and take the average of the remaining).
- The rightmost column is a description of the query arguments passed to datagrepper. Different kinds of queries take different times.
This first set of results are from our production instance as-is:
7.7467 "{'user': 'ralph', 'delta': 86400}"
0.6984 "{'category': 'buildsys', 'delta': 86400}"
0.7801 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'delta': 86400}"
6.0842 "{'not_package': 'bugwarrior', 'delta': 86400}"
7.9572 "{'category': 'buildsys', 'user': 'ralph'}"
7.2941 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'user': 'ralph'}"
11.751 "{'user': 'ralph', 'not_package': 'bugwarrior'}"
34.402 "{'category': 'buildsys', 'topic': 'org.fedoraproject.prod.buildsys.build.state.change'}"
36.377 "{'category': 'buildsys', 'not_package': 'bugwarrior'}"
44.536 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'not_package': 'bugwarrior'}"
Notice that a handful of queries are under one second but some are unbearably long. A seven second response time is too long, and a 44-second response time is way too long.
Setting up a dev instance
I grabbed the dump of our production database and imported it into a fresh postgres instance in our private cloud to mess around. Before making any further modifications, I ran the benchmarking script again on this new guy and got some different results:
5.4305 "{'user': 'ralph', 'delta': 86400}"
0.5391 "{'category': 'buildsys', 'delta': 86400}"
0.4992 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'delta': 86400}"
4.5578 "{'not_package': 'bugwarrior', 'delta': 86400}"
6.4852 "{'category': 'buildsys', 'user': 'ralph'}"
6.3851 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'user': 'ralph'}"
10.932 "{'user': 'ralph', 'not_package': 'bugwarrior'}"
9.1895 "{'category': 'buildsys', 'topic': 'org.fedoraproject.prod.buildsys.build.state.change'}"
14.950 "{'category': 'buildsys', 'not_package': 'bugwarrior'}"
12.044 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'not_package': 'bugwarrior'}"
A couple things are faster here:
- No ssl on the HTTP requests (almost irrelevant)
- No other load on the db from other live requests (likely irrelevant)
- The db was freshly imported (the last time we moved the db server things got magically faster. I think there's something about the way that postgres stores stuff internally that when you freshly import the data, it is organized more effectively. I have no data or real know-how to support this claim though).
Experimenting with indexes
I first tried adding indexes on the category and topic columns of the messages table (which are common columns used for filter operations). We already have an index on the timestamp column, without which the whole service is just unusable.
Some results after adding those:
0.1957 "{'user': 'ralph', 'delta': 86400}"
0.1966 "{'category': 'buildsys', 'delta': 86400}"
0.1936 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'delta': 86400}"
0.1986 "{'not_package': 'bugwarrior', 'delta': 86400}"
6.6809 "{'category': 'buildsys', 'user': 'ralph'}"
6.4602 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'user': 'ralph'}"
10.982 "{'user': 'ralph', 'not_package': 'bugwarrior'}"
3.7270 "{'category': 'buildsys', 'topic': 'org.fedoraproject.prod.buildsys.build.state.change'}"
14.906 "{'category': 'buildsys', 'not_package': 'bugwarrior'}"
7.6618 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'not_package': 'bugwarrior'}"
Response times are faster in the cases you would expect.
Those columns are relatively simple one-to-many relationships. A message has one topic, and one category. Topics and categories are each associated with many messages. There is no JOIN required.
Handling the many-to-many cases
Speeding up the queries that require filtering on users and packages is more tricky. They are many-to-many relations -- each user is associated with multiple messages and a message may be associated with many users (or many packages).
I did some research, and through trial-and-error found that adding a composite primary key on the bridge tables gave a nice performance boost. See the results here:
0.2074 "{'user': 'ralph', 'delta': 86400}"
0.2091 "{'category': 'buildsys', 'delta': 86400}"
0.2099 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'delta': 86400}"
0.2056 "{'not_package': 'bugwarrior', 'delta': 86400}"
1.4863 "{'category': 'buildsys', 'user': 'ralph'}"
1.4553 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'user': 'ralph'}"
1.8186 "{'user': 'ralph', 'not_package': 'bugwarrior'}"
3.5525 "{'category': 'buildsys', 'topic': 'org.fedoraproject.prod.buildsys.build.state.change'}"
10.9242 "{'category': 'buildsys', 'not_package': 'bugwarrior'}"
3.5214 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'not_package': 'bugwarrior'}"
The best so far! That one 10.9 second query is undesirable, but it also makes sense: we're asking it to first filter for all buildsys messages (the spammiest category) and then to prune those down to only the builds (a proper subset of that category). If you query just for the builds by topic and omit the category part (which is what you want anyways) the query takes 3.5s.
All around, I see a 3.5x speed increase.
Rolling it out
The code is set to be merged into datanommer and I wrote an ansible playbook to orchestrate pushing the change out. I'd push it out now, but we just entered the infrastructure freeze for the Fedora 22 Alpha release. Once we're through that and all thawed, we should be good to go.
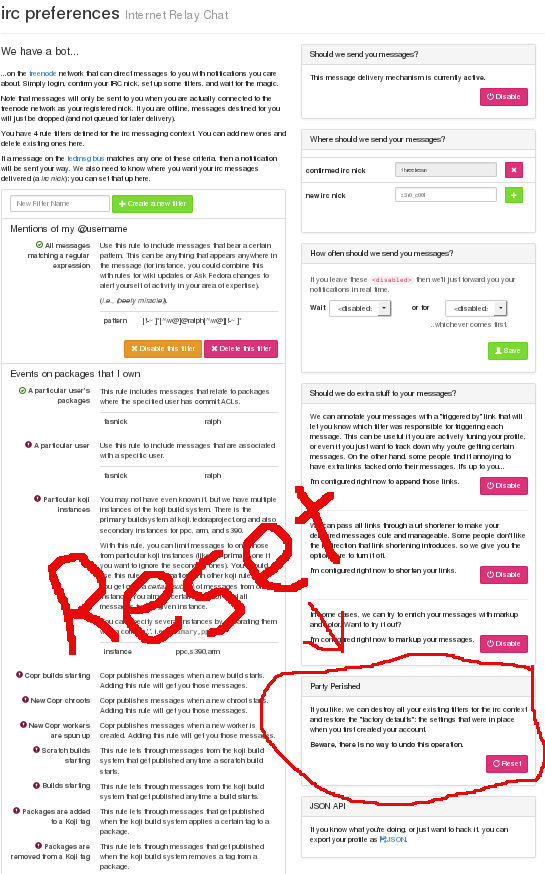
New FMN Release -- Improved Default Preferences
Jan 16, 2015 | categories: fmn, fedmsg, fedora View CommentsIt's been a while coming but this past week I released and deployed a new cut of FMN, Fedora's Fedmsg Notification system (it's a neat webapp that can send you notifications of events as they happen throughout Fedora Infrastructure). The release is full of bug fixes and little feature enhancements, I'll talk about a few here:
New defaults - this is the big one. The default settings were the biggest issue raised by early adopters. The complaints fell along two main axes: 1) the defaults deliver lots of messages that most users won't want and 2) the defaults are hard to understand and therefore hard to modify.
- In that first respect, the settings have been narrowed down greatly such that now you don't receive notifications about the bulk of your own activity. One of the most absurd cases was IRC meetings. If you were participating in an IRC meeting, you would get emails about topic changes in the IRC meeting you were already participating in. Clearly, you don't need an email about that.
- With the revised defaults, there are two main filters built: "Events on packages I own, except this kind, this kind, and that kind" and "Events involving my username, except this kind, this kind, and that kind." These are hopefully more intuitive to read and modify. Initial feedback from testers has been positive.
- There's also a new @mention filter that comes with the defaults which will notify you if someone references @your_fas_username anywhere in a fedmsg message, i.e. if someone adds @ralph in a fedorahosted trac ticket, I'll get a ping by IRC about it.
There's a button in the web interface you have to press to discard your current preferences and load in the new defaults. Try it out! Here's where you find it:
On to other new features, there is now a sensible digest mode for IRC that will collapse some collections of messages into one. It looks something like this:
- mschwendt and hobbes1069 commented on freecad-0.14-5.fc20,smesh-6.5.3.1-1.fc20
- limb changed sagitter's commit, watchcommits, and 2 others permissions on engauge-digitizer (epel7) to Approved
- kevin requested 2 xfdesktop stable updates for F21 and F20
- limb changed group::kde-sig's commit, watchcommits, and watchbugzilla permissions on ksysguard (f21, f20, and master) to Approved
- sagitter submitted 4 engauge-digitizer testing updates for F21, F20, and 2 others
- remi submitted 4 php-phpseclib-file-asn1 testing updates for F21, F20, and 2 others
Currently it can only collapse bodhi and pkgdb2 messages, but there will be more cases handled in the future (plus we can re-use this code for the new Fedora Hubs thing we're cooking up).
There is now a long form format for some messages over email. Specifically, git pushes to dist-git will include the patch in the email. If you have requests for other kinds of information you want forwarded to you, please file an RFE so we know what to prioritize.
Lastly, I'll say that making the most of FMN requires a little bit of imagination (which can be hard to do if you aren't already familiar with it). Here are some for custom filters you could build for your account:
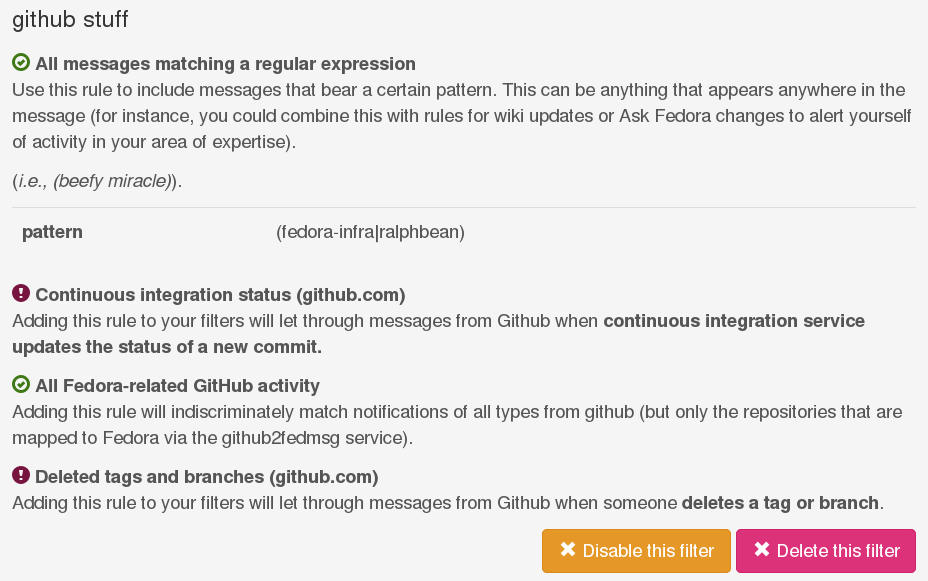
I get IRC notifications about all my github events now through FMN. I built a filter to forward messages that:
- are a github message
- match the regex (ralphbean|fedora-infra) (which simply means the message must contain either ralphbean or fedora-infra)
- are not continuous integration updates from Travis-CI.org (because those are spammy)
- are not deletions of tags or branches, since I don't care too much about those
And I use that to follow Fedora Infrastructure app development -- new pull requests, new issues, etc..
You could apply a similar scheme and build a filter to follow something in Fedora you're an expert at or want to learn more on. You could for instance build a filter for "systemd" like this:
- include messages that match the regex systemd
- ignore All messages from the Koji build system
- ignore All messages from dist-git SCM.
And you would be left with notifications from Ask Fedora anytime anyone asks a question about systemd and the wiki anytime some documentation gets updated that mentions systemd.
Anyways, please give the latest FMN a test and report any issues as you find them. Cheers!
Next Page »
 [three]Bean.org
[three]Bean.org