[three]Bean
Datanommer database migrated to a new db host
Sep 29, 2014 | categories: fedmsg, datanommer, fedora View CommentsThe bad news: our database of all the fedmsg messages ever - it's getting slower and slower. If you use datagrepper to query it with any frequency, you will have noticed this. The dynamics of it are simple: we are always storing new messages in postgres and none of them ever get removed. We're over 13 million messages now.
When we first launched datagrepper for public queries, they took around 3-4s to complete. We called this acceptable, and even fast enough to build services that relied extensively on it like the releng dashboard. As things got slower, queries could take around 60s and pages like the releng dash that made 20 some queries to it would take a long time to render fully.
Three Possible Solutions
We started looking at ways out of this jam.
NoSQL -- funny, the initial implementation of datanommer written on top of mongodb and we are now re-considering it. At Flock 2014, yograterol gave a talk on NoSQL in Fedora Infra which has sparked off a series of email threads and an experiment by pingou to import the existing postgres data into mongo. The next step there is to run some comparison queries when we get time to see if one backend is superior to the other in respects that we care about.
Sharding -- another idea is to horizontally partition our giant messages table in postgres. We could have one hot_messages table that holds only the messages from the last week or month, another warm_messages table that holds messages from the last 6 months or so, and a third cold_messages table that holds the rest of the messages from time immemorial. In one version of this scheme, no messages are duplicated between the tables and we have a cronjob that periodically (daily?) moves messages from hot to warm and from warm to cold. This is likely to increase performance for most use cases, since most people are only ever interested in the latest data on topic X, Y or Z. If someone is interested in getting data from way back in time, they typically also have the time to sit around and wait for it. All of this, of course, would be an implementation detail hidden inside of the datagrepper and datanommer packages. End users would simply query for messages as they do now and the service would transparently query the correct tables under the hood.
PG Tools -- While looking into all of this, we found some postgres tools that might just help our problems short term (although we haven't actually gotten a chance to try them yet). pg_reorg and pg_repack look promising. When preparing to test other options, we pulled the datanommer snapshot down and imported it on a cloud node and found, surprisingly, that it was much faster than our production instance. We also haven't had time to investigate this, but my bet is that when it is importing data for the first time, postgres has all the time in the world to pack and store the data internally in a way that it knows how to optimally query. This needs more thought -- if simple postgres tools will solve our problem, then we'll save a lot more engineering time than if we try to rewrite everything against mongo or rewrite everything against a cascade of tables (sharding).
Meanwhile
Doom arrived.
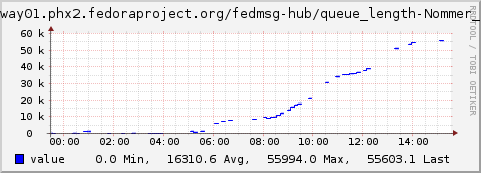
The above is a graph of the datanommer backlog from last week. The number on the chart represents how many messages have arrived in datanommer's local queue, but which have not been processed yet and inserted into the database. We want the number to be at 0 all the time -- indicating that messages are put into the database as soon as they arrive.
Last week, we hit an emergency scenario -- a critical point -- where datanommer couldn't store messages as fast as they were arriving.
Now.. what caused this? It wasn't that we were receiving messages at a higher than normal rate, it was that the database's slowness passed a critical point, the process of inserting a message was now taking too long, the rate at which we were processing messages was lower than necessary (see my other post on new measurements).
Migration
The rhel6 db host for datanommer was pegged so we decided to try and migrate it to a new rhel7 vm with more cpus as a first bet. This turned out to work much better than I expected.
Times for simple queries are down from 500 seconds to 4 seconds and our datanommer backlog graph is back down to zero.
The migration took longer than I expected and we have an unfortunate 2 hour gap in the datanommer history now. With some more forethought, we could get around this by standing up a temporary second db to store messages during the outage, and then adding those back to the main db afterwards. If we can get some spare cycles to set this up and try it out, maybe we can have it in place for next time.
For now, the situation seems to be under control but is not solved in the long run. If you have any interest in helping us with any of the three possible longer term solutions mentioned above (or have ideas about a fourth) please do join us in #fedora-apps on freenode and lend a hand.
 [three]Bean.org
[three]Bean.org