[three]Bean
Revisiting Datagrepper Performance
Feb 27, 2015 | categories: fedmsg, datanommer, fedora, datagrepper, postgres View CommentsIn Fedora Infrastructure, we run a service somewhat-hilariously called datagrepper which lets you make queries over HTTP about the history of our message bus. (The service that feeds the database is called datanommer.) We recently crossed the mark of 20 million messages in the store, and the thing still works but it has become noticeably slower over time. This affects other dependent services:
- The releng dashboard and others make HTTP queries to datagrepper.
- The fedora-packages app waits on datagrepper results to present brief histories of packages.
- The Fedora Badges backend queries the db directly to figure out if it should award badges or not.
- The notifications frontend queries the db to try an display what messages in the past would have matched a hypothetical set of rules.
I've written about this chokepoint before, but haven't had time to really do anything about it... until this week!
Measuring how bad it is
First, some stats -- I wrote this benchmarking script to try a handful of different queries on the service and report some average response times:
#!/usr/bin/env python import requests import itertools import time import sys url = 'https://apps.fedoraproject.org/datagrepper/raw/' attempts = 8 possible_arguments = [ ('delta', 86400), ('user', 'ralph'), ('category', 'buildsys'), ('topic', 'org.fedoraproject.prod.buildsys.build.state.change'), ('not_package', 'bugwarrior'), ] result_map = {} for left, right in itertools.product(possible_arguments, possible_arguments): if left is right: continue key = hash(str(list(sorted(set(left + right))))) if key in result_map: continue results = [] params = dict([left, right]) for attempt in range(attempts): start = time.time() r = requests.get(url, params=params) assert(r.status_code == 200) results.append(time.time() - start) # Throw away the max and the min (outliers) results.remove(min(results)) results.remove(min(results)) results.remove(max(results)) results.remove(max(results)) average = sum(results) / len(results) result_map[key] = average print "%0.4f %r" % (average, str(params)) sys.stdout.flush()
The results get printed out in two columns.
- The leftmost column is the average number of seconds it takes to make a query (we try 8 times, throw away the shortest and the longest and take the average of the remaining).
- The rightmost column is a description of the query arguments passed to datagrepper. Different kinds of queries take different times.
This first set of results are from our production instance as-is:
7.7467 "{'user': 'ralph', 'delta': 86400}"
0.6984 "{'category': 'buildsys', 'delta': 86400}"
0.7801 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'delta': 86400}"
6.0842 "{'not_package': 'bugwarrior', 'delta': 86400}"
7.9572 "{'category': 'buildsys', 'user': 'ralph'}"
7.2941 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'user': 'ralph'}"
11.751 "{'user': 'ralph', 'not_package': 'bugwarrior'}"
34.402 "{'category': 'buildsys', 'topic': 'org.fedoraproject.prod.buildsys.build.state.change'}"
36.377 "{'category': 'buildsys', 'not_package': 'bugwarrior'}"
44.536 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'not_package': 'bugwarrior'}"
Notice that a handful of queries are under one second but some are unbearably long. A seven second response time is too long, and a 44-second response time is way too long.
Setting up a dev instance
I grabbed the dump of our production database and imported it into a fresh postgres instance in our private cloud to mess around. Before making any further modifications, I ran the benchmarking script again on this new guy and got some different results:
5.4305 "{'user': 'ralph', 'delta': 86400}"
0.5391 "{'category': 'buildsys', 'delta': 86400}"
0.4992 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'delta': 86400}"
4.5578 "{'not_package': 'bugwarrior', 'delta': 86400}"
6.4852 "{'category': 'buildsys', 'user': 'ralph'}"
6.3851 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'user': 'ralph'}"
10.932 "{'user': 'ralph', 'not_package': 'bugwarrior'}"
9.1895 "{'category': 'buildsys', 'topic': 'org.fedoraproject.prod.buildsys.build.state.change'}"
14.950 "{'category': 'buildsys', 'not_package': 'bugwarrior'}"
12.044 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'not_package': 'bugwarrior'}"
A couple things are faster here:
- No ssl on the HTTP requests (almost irrelevant)
- No other load on the db from other live requests (likely irrelevant)
- The db was freshly imported (the last time we moved the db server things got magically faster. I think there's something about the way that postgres stores stuff internally that when you freshly import the data, it is organized more effectively. I have no data or real know-how to support this claim though).
Experimenting with indexes
I first tried adding indexes on the category and topic columns of the messages table (which are common columns used for filter operations). We already have an index on the timestamp column, without which the whole service is just unusable.
Some results after adding those:
0.1957 "{'user': 'ralph', 'delta': 86400}"
0.1966 "{'category': 'buildsys', 'delta': 86400}"
0.1936 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'delta': 86400}"
0.1986 "{'not_package': 'bugwarrior', 'delta': 86400}"
6.6809 "{'category': 'buildsys', 'user': 'ralph'}"
6.4602 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'user': 'ralph'}"
10.982 "{'user': 'ralph', 'not_package': 'bugwarrior'}"
3.7270 "{'category': 'buildsys', 'topic': 'org.fedoraproject.prod.buildsys.build.state.change'}"
14.906 "{'category': 'buildsys', 'not_package': 'bugwarrior'}"
7.6618 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'not_package': 'bugwarrior'}"
Response times are faster in the cases you would expect.
Those columns are relatively simple one-to-many relationships. A message has one topic, and one category. Topics and categories are each associated with many messages. There is no JOIN required.
Handling the many-to-many cases
Speeding up the queries that require filtering on users and packages is more tricky. They are many-to-many relations -- each user is associated with multiple messages and a message may be associated with many users (or many packages).
I did some research, and through trial-and-error found that adding a composite primary key on the bridge tables gave a nice performance boost. See the results here:
0.2074 "{'user': 'ralph', 'delta': 86400}"
0.2091 "{'category': 'buildsys', 'delta': 86400}"
0.2099 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'delta': 86400}"
0.2056 "{'not_package': 'bugwarrior', 'delta': 86400}"
1.4863 "{'category': 'buildsys', 'user': 'ralph'}"
1.4553 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'user': 'ralph'}"
1.8186 "{'user': 'ralph', 'not_package': 'bugwarrior'}"
3.5525 "{'category': 'buildsys', 'topic': 'org.fedoraproject.prod.buildsys.build.state.change'}"
10.9242 "{'category': 'buildsys', 'not_package': 'bugwarrior'}"
3.5214 "{'topic': 'org.fedoraproject.prod.buildsys.build.state.change', 'not_package': 'bugwarrior'}"
The best so far! That one 10.9 second query is undesirable, but it also makes sense: we're asking it to first filter for all buildsys messages (the spammiest category) and then to prune those down to only the builds (a proper subset of that category). If you query just for the builds by topic and omit the category part (which is what you want anyways) the query takes 3.5s.
All around, I see a 3.5x speed increase.
Rolling it out
The code is set to be merged into datanommer and I wrote an ansible playbook to orchestrate pushing the change out. I'd push it out now, but we just entered the infrastructure freeze for the Fedora 22 Alpha release. Once we're through that and all thawed, we should be good to go.
Datanommer database migrated to a new db host
Sep 29, 2014 | categories: fedmsg, datanommer, fedora View CommentsThe bad news: our database of all the fedmsg messages ever - it's getting slower and slower. If you use datagrepper to query it with any frequency, you will have noticed this. The dynamics of it are simple: we are always storing new messages in postgres and none of them ever get removed. We're over 13 million messages now.
When we first launched datagrepper for public queries, they took around 3-4s to complete. We called this acceptable, and even fast enough to build services that relied extensively on it like the releng dashboard. As things got slower, queries could take around 60s and pages like the releng dash that made 20 some queries to it would take a long time to render fully.
Three Possible Solutions
We started looking at ways out of this jam.
NoSQL -- funny, the initial implementation of datanommer written on top of mongodb and we are now re-considering it. At Flock 2014, yograterol gave a talk on NoSQL in Fedora Infra which has sparked off a series of email threads and an experiment by pingou to import the existing postgres data into mongo. The next step there is to run some comparison queries when we get time to see if one backend is superior to the other in respects that we care about.
Sharding -- another idea is to horizontally partition our giant messages table in postgres. We could have one hot_messages table that holds only the messages from the last week or month, another warm_messages table that holds messages from the last 6 months or so, and a third cold_messages table that holds the rest of the messages from time immemorial. In one version of this scheme, no messages are duplicated between the tables and we have a cronjob that periodically (daily?) moves messages from hot to warm and from warm to cold. This is likely to increase performance for most use cases, since most people are only ever interested in the latest data on topic X, Y or Z. If someone is interested in getting data from way back in time, they typically also have the time to sit around and wait for it. All of this, of course, would be an implementation detail hidden inside of the datagrepper and datanommer packages. End users would simply query for messages as they do now and the service would transparently query the correct tables under the hood.
PG Tools -- While looking into all of this, we found some postgres tools that might just help our problems short term (although we haven't actually gotten a chance to try them yet). pg_reorg and pg_repack look promising. When preparing to test other options, we pulled the datanommer snapshot down and imported it on a cloud node and found, surprisingly, that it was much faster than our production instance. We also haven't had time to investigate this, but my bet is that when it is importing data for the first time, postgres has all the time in the world to pack and store the data internally in a way that it knows how to optimally query. This needs more thought -- if simple postgres tools will solve our problem, then we'll save a lot more engineering time than if we try to rewrite everything against mongo or rewrite everything against a cascade of tables (sharding).
Meanwhile
Doom arrived.
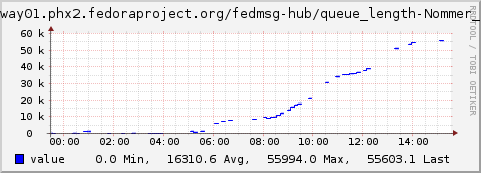
The above is a graph of the datanommer backlog from last week. The number on the chart represents how many messages have arrived in datanommer's local queue, but which have not been processed yet and inserted into the database. We want the number to be at 0 all the time -- indicating that messages are put into the database as soon as they arrive.
Last week, we hit an emergency scenario -- a critical point -- where datanommer couldn't store messages as fast as they were arriving.
Now.. what caused this? It wasn't that we were receiving messages at a higher than normal rate, it was that the database's slowness passed a critical point, the process of inserting a message was now taking too long, the rate at which we were processing messages was lower than necessary (see my other post on new measurements).
Migration
The rhel6 db host for datanommer was pegged so we decided to try and migrate it to a new rhel7 vm with more cpus as a first bet. This turned out to work much better than I expected.
Times for simple queries are down from 500 seconds to 4 seconds and our datanommer backlog graph is back down to zero.
The migration took longer than I expected and we have an unfortunate 2 hour gap in the datanommer history now. With some more forethought, we could get around this by standing up a temporary second db to store messages during the outage, and then adding those back to the main db afterwards. If we can get some spare cycles to set this up and try it out, maybe we can have it in place for next time.
For now, the situation seems to be under control but is not solved in the long run. If you have any interest in helping us with any of the three possible longer term solutions mentioned above (or have ideas about a fourth) please do join us in #fedora-apps on freenode and lend a hand.
Querying all package history from the command line
Jul 16, 2013 | categories: pkgwat, fedmsg, datanommer, fedora, datagrepper View CommentsAfter my last post on querying datagrepper, I wrote it into my pkgwat tool as the second-coolest subcommand: $ pkgwat history PKGNAME:
$ sudo yum -y install pkgwat $ pkgwat history firefox +------------+------------------------------------------------+---------------------+ | date | event | link | +------------+------------------------------------------------+---------------------+ | 2013/07/15 | stransky commented on bodhi update firefox-22. | http://ur1.ca/enmvg | | 2013/07/15 | suren commented on bodhi update firefox-22.0-1 | http://ur1.ca/enmvg | | 2013/07/10 | stransky's firefox-21.0-1.fc17 untagged from f | http://ur1.ca/eauo1 | | 2013/07/10 | xhorak's firefox-21.0-4.fc19 tagged into trash | http://ur1.ca/ea995 | | 2013/07/10 | xhorak's firefox-21.0-4.fc18 tagged into trash | http://ur1.ca/ea995 | | 2013/07/05 | stransky's firefox-20.0-3.fc20 tagged into tra | http://ur1.ca/ea995 | | 2013/07/04 | xhorak's firefox-21.0-4.fc19 untagged from f19 | http://ur1.ca/ea9a4 | | 2013/07/04 | xhorak's firefox-21.0-4.fc18 untagged from f18 | http://ur1.ca/ea9a1 | | 2013/07/03 | stransky's firefox-20.0-4.fc20 untagged from f | http://ur1.ca/ea9ac | | 2013/07/02 | pbrobinson's firefox-22.0-2.fc18 tagged into f | http://ur1.ca/ea9a1 | | 2013/07/02 | pbrobinson's firefox-22.0-2.fc18 completed | http://ur1.ca/enmvh | | 2013/07/02 | firefox-22.0-2.fc18 started building | http://ur1.ca/enmvh | +------------+------------------------------------------------+---------------------+
So the next time you're hacking on something and you say to yourself: "Wat wat wat. What just happened?" $ pkgwat history PKGNAME is another resource to draw on for clarity.
You can get the full help with $ pkgwat help history:
usage: pkgwat history [-h] [-f {csv,table}] [-c COLUMN]
[--quote {all,minimal,none,nonnumeric}]
[--rows-per-page ROWS_PER_PAGE] [--start-page PAGE]
package
Show the fedmsg history of a package. This command queries
https://apps.fedoraproject.org/datagrepper/
positional arguments:
package
optional arguments:
-h, --help show this help message and exit
--rows-per-page ROWS_PER_PAGE
--start-page PAGE
output formatters:
output formatter options
-f {csv,table}, --format {csv,table}
the output format, defaults to table
-c COLUMN, --column COLUMN
specify the column(s) to include, can be repeated
CSV Formatter:
--quote {all,minimal,none,nonnumeric}
when to include quotes, defaults to nonnumeric
Querying fedmsg history for package details by example
Jun 11, 2013 | categories: fedmsg, datanommer, fedora, datagrepper View CommentsIn case you missed it, you can query fedmsg history now with the datagrepper API.
I wrote up an example here to show how you might use it in a script. This will print out the whole history of the hovercraft package (at least everything that is published via fedmsg anyways). In time, I hope to add it to python-pkgwat-api and as a subcommand of the pkgwat command line tool. Until then, you can use:
#!/usr/bin/env python """ Query the history of a package using datagrepper! Check out the api at https://apps.fedoraproject.org/datagrepper/ :Author: Ralph Bean <rbean@redhat.com> :License: LGPLv2+ """ import datetime import re import requests regexp = re.compile( r'<p class="success">Your ur1 is: ' '<a href="(?P<shorturl>.+)">(?P=shorturl)</a></p>') def shorten_url(longurl): response = requests.post("http://ur1.ca/", data=dict(longurl=longurl)) return regexp.search(response.text).groupdict()['shorturl'] def get_data(package, rows=20): url = "https://apps.fedoraproject.org/datagrepper/raw/" response = requests.get( url, params=dict( package=package, delta=9999999, meta=['subtitle', 'link'], rows_per_page=rows, order='desc', ), ) data = response.json() return data.get('raw_messages', []) def print_data(package, links=False): for message in get_data(package, 40): dt = datetime.datetime.fromtimestamp(message['timestamp']) print dt.strftime("%Y/%m/%d"), print message['meta']['subtitle'], if links: print shorten_url(message['meta']['link']) else: print if __name__ == '__main__': print_data(package='hovercraft', links=False)
And here's the output:
- 2013/06/10 ralph's hovercraft-1.1-3.fc18 untagged from f18-updates-pending by bodhi http://ur1.ca/ea99c
- 2013/06/10 ralph's hovercraft-1.1-3.fc18 tagged into f18-updates by bodhi http://ur1.ca/ea99e
- 2013/06/10 ralph's hovercraft-1.1-3.fc18 untagged from f18-updates-testing by bodhi http://ur1.ca/ea99f
- 2013/06/10 ralph's hovercraft-1.1-3.fc19 tagged into f19-updates-pending by bodhi http://ur1.ca/ea99x
- 2013/06/10 ralph's hovercraft-1.1-3.fc18 tagged into f18-updates-pending by bodhi http://ur1.ca/ea99c
- 2013/06/10 ralph submitted hovercraft-1.1-3.fc18 to stable http://ur1.ca/ea99y
- 2013/06/10 ralph submitted hovercraft-1.1-3.fc19 to stable http://ur1.ca/ea99z
- 2013/05/21 ralph's hovercraft-1.1-3.fc18 untagged from f18-updates-testing-pending by bodhi http://ur1.ca/ea9a0
- 2013/05/21 ralph's hovercraft-1.1-3.fc18 tagged into f18-updates-testing by bodhi http://ur1.ca/ea99f
- 2013/05/21 ralph's hovercraft-1.1-3.fc18 untagged from f18-updates-candidate by bodhi http://ur1.ca/ea9a1
- 2013/05/21 ralph's hovercraft-1.1-3.fc19 untagged from f19-updates-testing-pending by bodhi http://ur1.ca/ea9a2
- 2013/05/21 ralph's hovercraft-1.1-3.fc19 tagged into f19-updates-testing by bodhi http://ur1.ca/ea9a3
- 2013/05/21 ralph's hovercraft-1.1-3.fc19 untagged from f19-updates-candidate by bodhi http://ur1.ca/ea9a4
- 2013/05/21 ralph's hovercraft-1.1-3.fc18 tagged into f18-updates-testing-pending by bodhi http://ur1.ca/ea9a0
- 2013/05/21 ralph submitted hovercraft-1.1-3.fc18 to testing http://ur1.ca/ea99y
- 2013/05/21 ralph's hovercraft-1.1-3.fc17 failed to build http://ur1.ca/ea9a5
- 2013/05/21 hovercraft-1.1-3.fc17 started building http://ur1.ca/ea9a5
- 2013/05/21 ralph pushed to hovercraft (f17). "Add BR on python3-manuel." http://ur1.ca/ea9a6
- 2013/05/21 ralph's hovercraft-1.1-3.fc18 tagged into f18-updates-candidate by ralph http://ur1.ca/ea9a1
- 2013/05/21 ralph's hovercraft-1.1-3.fc18 completed http://ur1.ca/ea9a7
- 2013/05/21 hovercraft-1.1-3.fc18 started building http://ur1.ca/ea9a7
- 2013/05/21 ralph pushed to hovercraft (f18). "Add BR on python3-manuel." http://ur1.ca/ea9a8
- 2013/05/20 ralph's hovercraft-1.1-3.fc19 tagged into f19-updates-testing-pending by bodhi http://ur1.ca/ea9a2
- 2013/05/20 ralph submitted hovercraft-1.1-3.fc19 to testing http://ur1.ca/ea99z
- 2013/05/20 ralph's hovercraft-1.1-3.fc19 tagged into f19-updates-candidate by ralph http://ur1.ca/ea9a4
- 2013/05/20 ralph's hovercraft-1.1-3.fc19 completed http://ur1.ca/ea9ab
- 2013/05/20 ralph's hovercraft-1.1-3.fc20 tagged into f20 by ralph http://ur1.ca/ea9ac
- 2013/05/20 ralph's hovercraft-1.1-3.fc20 completed http://ur1.ca/ea9ad
- 2013/05/20 hovercraft-1.1-3.fc19 started building http://ur1.ca/ea9ab
- 2013/05/20 hovercraft-1.1-3.fc20 started building http://ur1.ca/ea9ad
- 2013/05/20 ralph pushed to hovercraft (f19). "Add BR on python3-manuel." http://ur1.ca/ea9ae
- 2013/05/20 ralph pushed to hovercraft (master). "Add BR on python3-manuel." http://ur1.ca/ea9af
- 2013/05/20 ralph's hovercraft-1.1-2.fc19 failed to build http://ur1.ca/ea9ag
- 2013/05/20 hovercraft-1.1-2.fc19 started building http://ur1.ca/ea9ag
- 2013/05/20 ralph's hovercraft-1.1-2.fc19 failed to build http://ur1.ca/ea9ag
- 2013/05/20 hovercraft-1.1-2.fc19 started building http://ur1.ca/ea9ag
- 2013/05/20 ralph's hovercraft-1.1-2.fc19 failed to build http://ur1.ca/ea9ag
- 2013/05/20 hovercraft-1.1-2.fc19 started building http://ur1.ca/ea9ag
- 2013/05/20 ralph's hovercraft-1.1-2.fc19 failed to build http://ur1.ca/ea9ag
- 2013/05/20 hovercraft-1.1-2.fc19 started building http://ur1.ca/ea9ag
Querying fedmsg history
May 14, 2013 | categories: fedmsg, datanommer, fedora, datagrepper View CommentsYesterday, Ian Weller and I got the first iteration of "datagrepper" into production. It is a JSON api that lets you query the history of the fedmsg bus. In case you're confused.. it is related to, but not the same thing as "datanommer". You can check out the datagrepper docs on its index page as well as on its reference page.
It is another building block. With it, we can now:
- Use it as a reliability resource for other fedmsg projects.
- Say you have a daemon that listens for fedmsg messages to act on... but it crashes. When it gets restarted it can ask datagrepper "What messages did I miss since this morning at 4:03am?" and catch up on those as it can.
- Build apps that query it to show "the latest so many messages
that meet such and such criteria."
- Imagine an HTML5 mobile app that shows you the latest of anything and everything in Fedora. (pingou is at work on this).
- Imagine package-centric UI widgets that show the latest Fedora-wide events pertaining to a certain package. We could embed them in the Fedora Packages app.
- Imagine user-centric UI widgets that show the latest activity of developers. You could embed yours in your blog or wiki page.
- Statistics! The whole dataset is available to you and updated in real time. Can you tell any cool stories with it?
It is, like I mentioned, an initial release so please be gentle. We have a big list of plans and bugs to crack on. If you run into issues or simply have questions, feel free to file a bug or ping us in #fedora-apps on freenode.
Next Page »
 [three]Bean.org
[three]Bean.org