[three]Bean
Backend rewrite of the Fedora-Packages webapp
Nov 20, 2015 | categories: python, cache, fedora View CommentsJust yesterday, we deployed the 3.0 version -- a rewrite -- of the fedora-packages webapp (source). For years now, it has suffered from data corruption problems that stemmed from multiple processes all fighting over resources stored on a gluster share between the app nodes. Gluster's not to blame. It's that too many things were trying to be "helpful" and no amount of locking would seem to solve the problem.
tl;dr
We have lots of old, open tickets about various kinds of data being missing from the webapp. Those are hopefully all resolved now. Please use it and file new tickets if you notice bugs. Patience appreciated.
Architecture
Let's take a look at the internal architecture of the app. It's a cool idea. It doesn't really have any data of its own, but it is a layer on top of our other packaging apps; it just re-presents all of their data in one place. This is the "microservices" dream?
Here we have a diagram of the system as it was originally written in its "2.0" state.
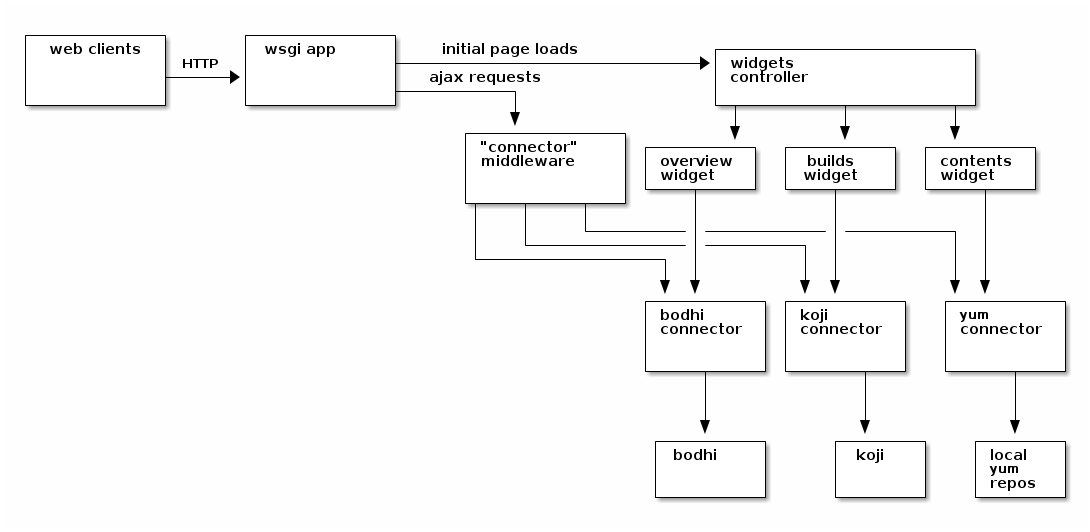
HTTP requests come in to the app either for some initial page load or for some kind of subsequent ajax data. The app hands control off to one of two major subsystems -- a "widgets" controller that handles rendering all the tabs, and a "connectors" dispatcher that handles gathering and returning data. The widgets themselves actually re-use the connectors under the hood to prepare their initial data.
More complicated than that
First, there are only three widgets/connectors depicted above, but really there are many more (a search connector, a bugzilla connector, etc..). Some of them were written, but never included any place in the app (in the latest pass through the code, I found an unused TorrentConnector which returned data about Fedora torrent downloads!).
Note that over the last few years, the widgets subsystem has remained largely unchanged. It is a source of technical debt, but it hasn't been the cause of any major breakages, so we haven't had cause to touch it. The widgets have metaclasses under the hood, can be nested into a hierarchy, and can declare js/css resource dependencies in a tree. It's pretty massive -- all on the server-side.
There is also (not depicted) an impenetrable thicket of javascript that gets served to clients which in turn wires up a lot of the client-side behavior.
Lastly, there are (were) a variety of cronjobs (not depicted) which would update local data for a subset of the connectors. Notably, there was a yum-sync cronjob that would pull the latest yum repodata down to disk. There was a cronjob that would pull down all the latest koji builds "since the last time it ran". Another would crawl through the local yum repos and rebuild the search index based on what it thought was in rawhide.
Just... keep all that in mind.
Focus on the connectors
Here's a simpler drawing:
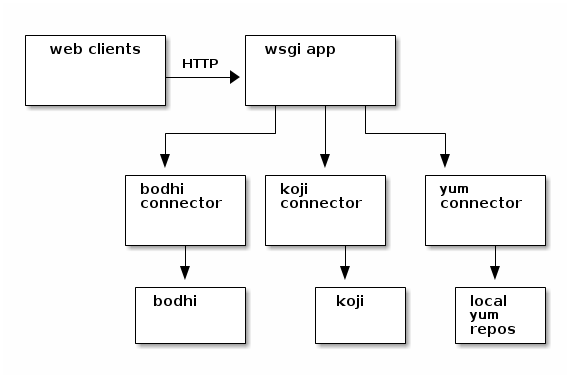
So, when it was first released, this beast was too slow. The koji connector would take forever to return.. and bugzilla even longer.
To try and make things snappy, I added a cache layer internally, like this:
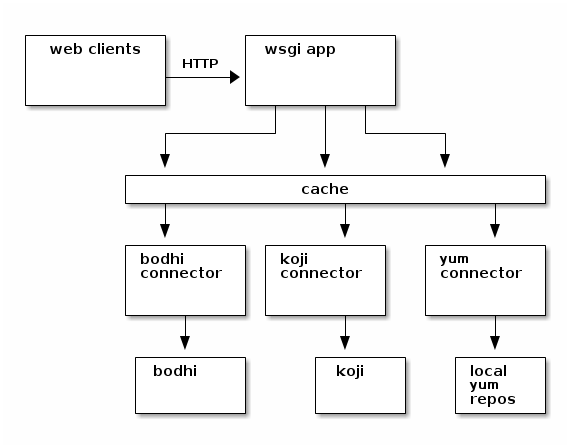
The "connector middleware" and the widget subsystem would both use the cache, and things became somewhat more nice! However, the cache expiry was too long, and people complained (rightly) that the data was often out of date. So, we reduced it and had the cache expire every 5 minutes. But.. that defeated the whole point. Every time you requested a page, you were almost certainly guaranteed that the cache would already be expired and you'd have to wait and wait for the connectors to do their heavy-lifting anyways.
Async Refresh
That's when (back in 2013), I got this idea to introduce an asynchronous cache worker, that looked something like this.
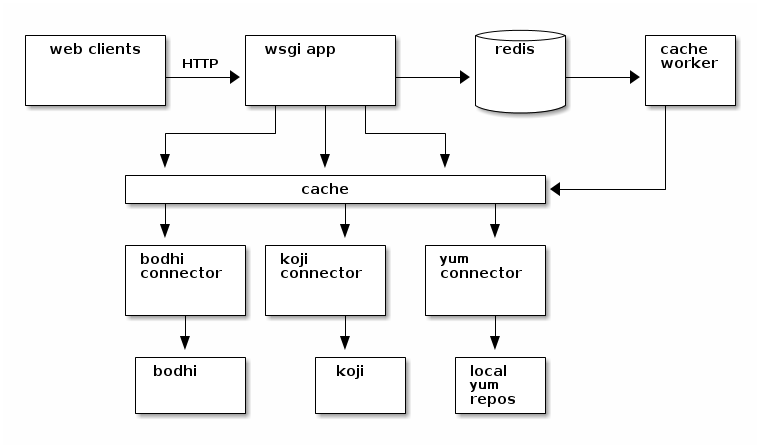
If you requested a page and the cache data was too old, the web app would just return the old data to you anyways, but it would also stick a note in a redis queue telling a cache worker daemon that it should rebuild that cache value for the next request.
I thought it was pretty cool. You could request the page and sometimes get old data, but if you refreshed shortly after that you'd have the new stuff. Pages that were "hot" (being clicked on by multiple people) appeared to be kept fresh more regularly.
However, a page that was "cold" -- something that someone would visit once every few months -- would often present horribly old information to the requester. People frequently complained that the app was just out of sync entirely.
To make matters worse, it was out of sync entirely! We had a separate set of issues with the cron jobs (the one that would update the list of koji builds and the one that would update the yum cache). Sometimes, the webapp, the cache worker, and the cronjob would all try to modify the same files at the same time and horribly corrupt things. The cronjob would crash, and it would never go back to find the old builds that it failed to ingest. It was a mess.
The latest rewrite
Two really good decisions were made in the latest rewrite:
First, we dispensed entirely with the local yum repos (which were the resources most prone to corruption). We moved that out to an external network service called mdapi which is very cool in its own right, but it makes the data story much more simple for the fedora-packages app.
Second, I replaced the reactive async cache worker with an active event-driven cache worker. Instead of updating the cache when a user requests the page, we update the cache when the resources change in the system we would query. For example, when someone does a new build in the buildsystem, the buildsystem publishes a message to our message bus. The cache worker receives that event -- it first deletes the old JSON data for the builds page for that package in the cache, and then it calls the KojiConnector with the appropriate arguments to re-fill that cache value with the latest data.
We turned off expiration in the cache all-together so that values never expire on their own. The outcome here is that the page data should be freshly cached before anyone requests it -- active cache invalidation.
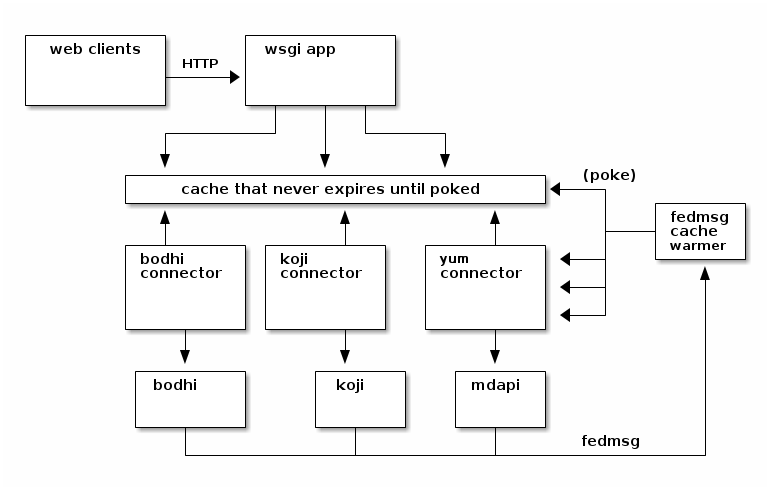
With those two changes, we were able to kill off all of the cronjobs.
Some additional complications: first, the cache worker also updates a local xapian database in response to events (in addition to the expiration-less cache), but it is the only process doing so and so can hopefully avoid further corruption issues.
Second, the bugzilla connector can't work like this yet because we don't yet have bugzilla events on our message bus. Zod-willing, we'll have them in January 2016 and we can flip that part on. The bugs tab will be slower than we like until then. UPDATE: We got bugzilla on the bus at the end of March, 2016.
Looking forwards
We're building the fedora-hubs backend with the same kind of architecture (actively-invalidated cache of tough-to-assemble page data), so, we get to learn practical lessons here about what works and what doesn't.
Do hit us up in #fedora-apps on freenode if you want to help out, chat, or lurk. I'll be cleaning up any loose bugs on this deployment in the coming weeks while starting work on a new pdc-updater project.
Upcoming Python3 Porting vFAD
Nov 02, 2015 | categories: python, fedora View CommentsAll thanks to Abdel Martínez and Matej Stuchlik, we're going to be holding a (virtual) international "Fedora Activity Day" for Python 3 porting, and it is going to be amazing. Save the date -- November 14th and 15th

Things to consider:
- If you haven't heard, 2016 is going to be the year of Python3 on the desktop, so...
- If you don't know what you're doing with Python3 porting, don't sweat it. If you want to learn, come join and we'll try to teach you along the way.
- If you don't know how to submit patches upstream, don't sweat it. If you want to learn, come join and we'll try to teach you along the way.
- If you want to hack with us, add your info to the wiki page. We'll be hanging out in a opentokrtc channel and in #fedora-python on freenode. See the details.
- We have a really cool webapp that Petr Viktorin put together. It tracks the status of different packages in Fedora and upstream so we can coordinate more effectively about what needs to be done.
- If you want to get people in your city together, that can make it more fun. You can join the video chat as a group! The EMEA crew will be online from the Pycon CZ 2015 sprints (cool). There are a couple people from my local Python User Group that want to join in.. although we're still searching for a reasonable place to meet up. I plan to be around starting at 18:00 UTC both days, although I bet EMEA crew will be online much earlier.
Happy Hacking
Going to Flock? 10 things to do in Rochester
Aug 06, 2015 | categories: flock, rochester, fedora View CommentsWe're less than a week out from Fedora Flock 2015 in Rochester. We're going to be super busy with planned sessions and hackfests during the day and parties at night, but if you find yourself with some downtime or if you just need a breather, here are some things around the Flower City to check out.
Daytime things
#1 Walk to Hart's local grocers (map1) for anything you might need. They have good prepared food and all sorts of fresh fixin's.
#2 Especially the vegetarians, check out Orange Glory (map2) for a sandwich wonderland (they have some meaty sandwiches too, fwiw).

#3 Get your fancy coffees at Java's Cafe (map3). It's a great spot (and my partner works there so be nice!)

#4 High Falls doesn't hold a candle to Niagara Falls, but it's still pretty cool. There's a good view from the walkable Genesee Brew House (map4) (which has good beer and food).

#5 Take a walk in Mount Hope Cemetery (map5) It's a beautiful 200 acres, home to such notable burials as Frederick Douglass and Susan B. Anthony.

#6 The super adventurous types might want to explore Rochester's abandoned subway system, although you'll have to find an entrance -- not for the faint of heart.

Nighttime things
#7 Beer lovers should almost certainly visit the Old Toad (map7). A walk there is worth it (and there are lots of other bars and clubs nearby in the "East End").

#8 Nearby is the Skylark Lounge (map8). I'm not even kidding when I say they have the best meatballs in the city.

#9 Eat a garbage plate, preferably late at night. The best ones are at Mark's Texas Hots (map9).

#10 Lastly, you can eat a more-than-reasonable amount of pulled pork at Dinosaur Bar-B-Que (map10).

Speeding up that nose test suite.
Jun 23, 2015 | categories: python, fedmsg, fedora, nose View CommentsShort post: I just discovered the --with-prof option to the nosetests command. It profiles your test suite by using the hotshot module from the Python standard library and it found a huge sore spot in my most frequently run suite. In this pull request we got the fedmsg_meta running 31x faster.
Compare before:
(fedmsg_meta)❯ time $(which nosetests) -x Ran 3822 tests in 270.822s OK (SKIP=1638) ---------------------------------------------------------------------- Success! $(which nosetests) -x 267.30s user 1.32s system 98% cpu 4:33.53 total
And after:
(fedmsg_meta)❯ time $(which nosetests) -x Ran 3822 tests in 5.982s OK (SKIP=1638) ---------------------------------------------------------------------- Success! $(which nosetests) -x 3.87s user 0.71s system 52% cpu 8.700 total
That test suite used to take forever. It's the whole reason I wrote nose-audio in the first place!
Some notes from the releng FAD
Jun 15, 2015 | categories: releng, fedora, koji View CommentsA number of us were funded to come together last weekend for a release engineering FAD in Westford. I'll save summaries of the whole event for writeups by others, but I will say that we planned work on the first day with an 'agile' exercise proposed and facilitated by imcleod. It worked well and mitigated any centrifugal forces acting on the FAD.
Read Adam Miller's post for a solid summary of the whole event. Here's just a run down of the things I personally got involved in:
The runroot plugin - we've been talking about it forever -- an Internet search reveals a mention of it from a meeting in 2007 <http://fedoraproject.org/wiki/Extras/SteeringCommittee/Meeting-20070315>. What finally made it a necessity is pungi4. We're hoping to move the compose to using that, and it in turn relies on the runroot plugin in koji to do most of its work.
A portion of it was open sourced last year. I got it installed in staging and then found we were missing some more parts to it. We sorted those all out, submitted some patches upstream to koji and got a staging proof of concept working. As of last week, we have it in production and a new channel of builders dedicated to it.
Our staging koji instance was originally setup last year at the Bodhi2 FAD using the external repos feature of koji. This worked well enough for testing scratch builds and little things like that, but was insufficient for testing some larger parts of the releng process (the compose). We compared some options and have settled on a solution. Some pieces of that puzzle have been implemented but I've yet to finish putting it all together. Hopefully done this week.
As far as planning goes, I thought the koji 2.0 discussions were quite fruitful, and I'm really excited at how the architecture it shaping up.
We also had some good interstitial sessions talking about role and requirements for what has been heretofore called the ComposeDB. There's still more discussion to have before we can land on a planning document for it, but fwiw, we think we have a much better name for it than ComposeDB.
I'll end with noting that on the day before the FAD started, a number of us got together to plan for and hack on Fedora Hubs. decause and I stayed up late almost every night and wrote some pretty neat proofs of concept for it. There's good stuff running now in the prototype if you want to try to get it running on your local system. Fun, fun. Happy Hacking!
« Previous Page -- Next Page »
 [three]Bean.org
[three]Bean.org