[three]Bean
New FMN Release -- Improved Default Preferences
Jan 16, 2015 | categories: fmn, fedmsg, fedora View CommentsIt's been a while coming but this past week I released and deployed a new cut of FMN, Fedora's Fedmsg Notification system (it's a neat webapp that can send you notifications of events as they happen throughout Fedora Infrastructure). The release is full of bug fixes and little feature enhancements, I'll talk about a few here:
New defaults - this is the big one. The default settings were the biggest issue raised by early adopters. The complaints fell along two main axes: 1) the defaults deliver lots of messages that most users won't want and 2) the defaults are hard to understand and therefore hard to modify.
- In that first respect, the settings have been narrowed down greatly such that now you don't receive notifications about the bulk of your own activity. One of the most absurd cases was IRC meetings. If you were participating in an IRC meeting, you would get emails about topic changes in the IRC meeting you were already participating in. Clearly, you don't need an email about that.
- With the revised defaults, there are two main filters built: "Events on packages I own, except this kind, this kind, and that kind" and "Events involving my username, except this kind, this kind, and that kind." These are hopefully more intuitive to read and modify. Initial feedback from testers has been positive.
- There's also a new @mention filter that comes with the defaults which will notify you if someone references @your_fas_username anywhere in a fedmsg message, i.e. if someone adds @ralph in a fedorahosted trac ticket, I'll get a ping by IRC about it.
There's a button in the web interface you have to press to discard your current preferences and load in the new defaults. Try it out! Here's where you find it:
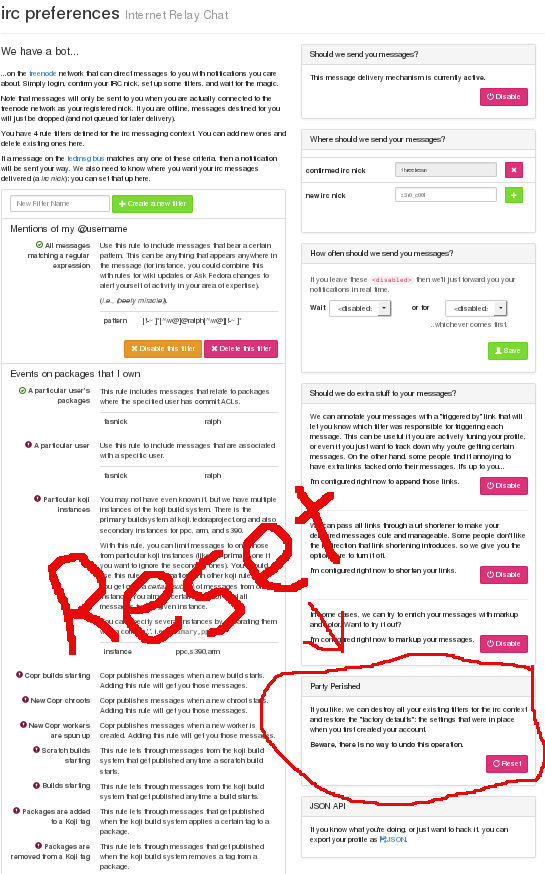
On to other new features, there is now a sensible digest mode for IRC that will collapse some collections of messages into one. It looks something like this:
- mschwendt and hobbes1069 commented on freecad-0.14-5.fc20,smesh-6.5.3.1-1.fc20
- limb changed sagitter's commit, watchcommits, and 2 others permissions on engauge-digitizer (epel7) to Approved
- kevin requested 2 xfdesktop stable updates for F21 and F20
- limb changed group::kde-sig's commit, watchcommits, and watchbugzilla permissions on ksysguard (f21, f20, and master) to Approved
- sagitter submitted 4 engauge-digitizer testing updates for F21, F20, and 2 others
- remi submitted 4 php-phpseclib-file-asn1 testing updates for F21, F20, and 2 others
Currently it can only collapse bodhi and pkgdb2 messages, but there will be more cases handled in the future (plus we can re-use this code for the new Fedora Hubs thing we're cooking up).
There is now a long form format for some messages over email. Specifically, git pushes to dist-git will include the patch in the email. If you have requests for other kinds of information you want forwarded to you, please file an RFE so we know what to prioritize.
Lastly, I'll say that making the most of FMN requires a little bit of imagination (which can be hard to do if you aren't already familiar with it). Here are some for custom filters you could build for your account:
I get IRC notifications about all my github events now through FMN. I built a filter to forward messages that:
- are a github message
- match the regex (ralphbean|fedora-infra) (which simply means the message must contain either ralphbean or fedora-infra)
- are not continuous integration updates from Travis-CI.org (because those are spammy)
- are not deletions of tags or branches, since I don't care too much about those
And I use that to follow Fedora Infrastructure app development -- new pull requests, new issues, etc..
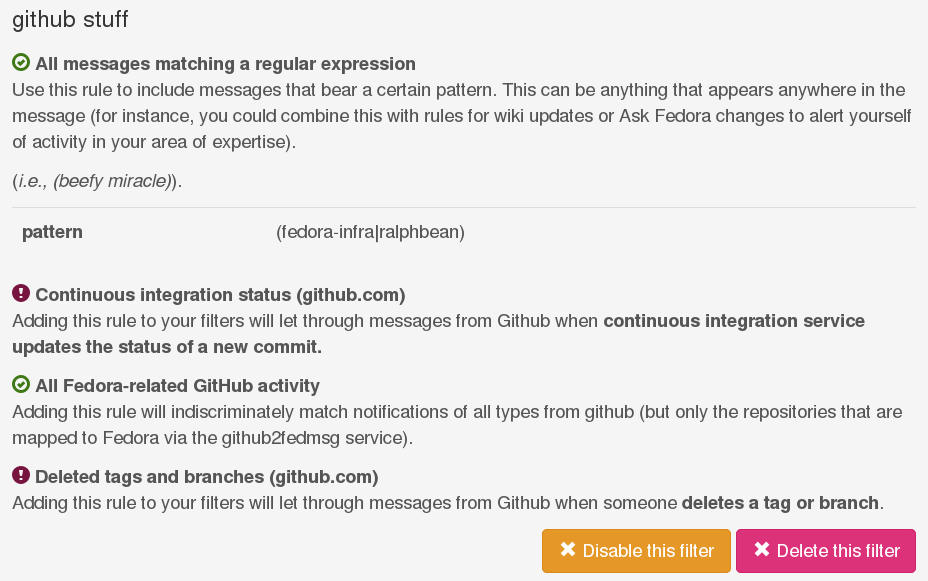
You could apply a similar scheme and build a filter to follow something in Fedora you're an expert at or want to learn more on. You could for instance build a filter for "systemd" like this:
- include messages that match the regex systemd
- ignore All messages from the Koji build system
- ignore All messages from dist-git SCM.
And you would be left with notifications from Ask Fedora anytime anyone asks a question about systemd and the wiki anytime some documentation gets updated that mentions systemd.
Anyways, please give the latest FMN a test and report any issues as you find them. Cheers!
Infrastructure FAD Report -- MirrorManager2/Ansible
Dec 11, 2014 | categories: mirrormanager, ansible, fedora, fad View CommentsLast week we held a FAD to work on mirrormanager2 and ansible (where mirrormanager2 is the rewrite of mirrormanager1 and where by ansible we mean the Fedora Infrastructure team's ansible setup).
Mirrormanager2
pingou wrote about it already but the mirrormanager2 portion of the hackfest went well. We had mdomsch with us (the original author of mirrormanager1) and we spent almost the entire first day just picking his brain -- asking questions to try and learn all the why's and how's of mirrormanager1. pingou had done a lot of work before hand getting the web frontend rewritten in Flask, the mirrorlist server needed some changes, but not an overhaul (lmacken ported it away from paste to webob and wrote a much needed test suite). Lots of time was spent on the gaggle of cron jobs and update scripts that perform various maintenance tasks on the database.
Two of the big ones are a local crawler (called "umdl") and a remote crawler (called "crawler"). UMDL stands for "update master directory list": it crawls the tree that Release Engineering has published to figure out what should be mirrored. Mirrors take care of rsyncing that content themselves, but with this "should" list handy, the remote crawler can then later check which mirrors do and do not have the latest content. With that who-has-what list, the mirrorlist server can then produce dynamically updated lists of where you should and shouldn't get your yum updates from.
I spent most of my time on those two. In common: I updated them to produce fedmsg messages when they start and complete their work and to work against the new database model. I added some code to UMDL to identify and remember ostree repos for Fedora Atomic and the remote crawler got a refactoring too (moving from two scripts with a process manager into one script with a thread pool), thus removing a couple hundred lines of code, leveraging the Python standard library.
It's on its way to staging now and will get to simmer there for a while before we roll it out.
Ansible
nirik wrote about it [1] [2] [3]... we did a wild amount of work on our ansible setup. 287 commits:
❯ git log --after 2014-12-03 --before 2014-12-09 --oneline | wc -l 287
There was enough going on among the group that I don't have a good handle on what all got done -- it was a lot! I worked on two things primarily:
With oddshocks, we got the fedimg AWS image uploader working in staging and pushed out to production.
For the last two days of the FAD, I got almost all of the sprawling metropolis that is our proxy layer ported over from puppet to ansible. It's something that wasn't fun, and doesn't really give us any new features to speak of.. but it's something that's been bugging me for over a year now. Everytime we add a new app or migrate one from puppet to ansible, we have to leave some proxy configuration for it over in the puppet repo, contributing to a split-brain scenario between our config management systems.
Porting over the proxy layer involves touching everything. Every app has an entry there, every request has to go through it (and haproxy and varnish (sometimes)). It's something that could only get done in the company of the rest of the team, with sustained effort, and with nothing else demanding our attention; a perfect candidate for the FAD. There's a few loose ends to tie it up, but I'm glad to call it "almost done".
Two mistakes
In general, FADs seem to be really effective for the infrastructure team. We got boatloads done at the bodhi2 FAD back in June -- same for this one. If there was a drawback this time, it's that we didn't have any explicitly planned social events. We went out for beers each night, but a lot of time we ended up just talking more about what we were working on that day and next. Day after day for a weeklong sprint, that left us pretty crispy by the end. We'd say "oh, let's take a break and get lunch around this or that time" and hours would pass only to find ourselves still working at 6 or 7pm. Having scheduled breaks with something to do other than sit around and talk about what we're hacking on would help deflect burnout. On the last night, lmacken and I went out to play a poker game before catching planes back home in the morning. It would be cool to get the whole participation of the FAD in something next time.
The scheduling of this one ended up unlucky. We were half hacking on mirrormanager (unimpeded) and half hacking on our ansible setup -- while on the last week of the final release freeze for Fedora 21. The day we flew home was release day! We were all exhausted just in time for the shenanigans that nirik has written about here.
All in all: FAD -> good, a success. I need to grab a nap and then finish off that proxy layer port.. ;) Happy hacking.
Trying to Understand Koji Tags (i need a picture...)
Nov 12, 2014 | categories: releng, graphviz, fedora, koji View CommentsOver the past few days I've been trying to replicate our release-engineering infrastructure in our staging environment so we can try out changes with less worry, move faster in the future, etc. There been some progress but there are a lot of pieces -- this won't be done for a while.
The latest subject of my efforts has been koji. I had some authentication problems off the bat but I got it to the point now so that it is pulling it's CRL correctly from FAS. You can edit /etc/koji.conf and actually point your builds at it. It only has one builder (all we need) but they'll run and complete!:
[koji] ;server = http://koji.fedoraproject.org/kojihub ;weburl = http://koji.fedoraproject.org/koji ;topurl = https://kojipkgs.fedoraproject.org/ server = http://koji.stg.fedoraproject.org/kojihub weburl = http://koji.stg.fedoraproject.org/koji topurl = https://kojipkgs.stg.fedoraproject.org/
I even have the kojira service running now (it is a background service responsible for rebuilding and maintaining the repos that hang off of https://koji.fedoraproject.org/repos/ -- notably the rawhide/ one that I'm interested in for performing fake staging 'composes'. It is notoriously absent from the staging repos.)
This led me into the dark nest that is koji tags and targets. I've been using them for years to build my packages, but I never really understood how they all fit together and what was even the difference between a tag and a target. I wrote the following graph-generating script the try and make sense:
#!/usr/bin/env python """ koji2graphviz.py - Visualize Koji Tags and their relationships. Author: Ralph Bean <rbean@redhat.com> License: LGPLv2+ """ import multiprocessing.pool import sys from operator import itemgetter as getter import koji # https://pypi.python.org/pypi/graphviz from graphviz import Digraph N = 40 graph_options = {'format': 'png'} tags_parent_child = Digraph( name='tags_parent_child', comment='Koji Tags, Parent/Child relationships', **graph_options) tags_groups = Digraph( name='tags_groups', comment='Koji Tags and what Groups they are in', **graph_options) tags_and_targets = Digraph( name='tags_and_targets', comment='Koji Tags and Targets', **graph_options) client = koji.ClientSession('https://koji.fedoraproject.org/kojihub') tags = client.listTags() for tag in tags: tags_parent_child.node(tag['name'], tag['name']) def get_relations(tag): sys.stdout.write('.') sys.stdout.flush() idx = tag['id'] return (tag, { 'parents': client.getInheritanceData(tag['name']), 'group_list': sorted(map(getter('name'), client.getTagGroups(idx))), 'dest_targets': client.getBuildTargets(destTagID=idx), 'build_targets': client.getBuildTargets(buildTagID=idx), 'external_repos': client.getTagExternalRepos(tag_info=idx), }) print "getting parent/child relationships with %i threads" % N pool = multiprocessing.pool.ThreadPool(N) relationships = pool.map(get_relations, tags) print print "got relationships for all %i tags" % len(relationships) print "collating known groups" known_groups = list(set(sum([ data['group_list'] for tag, data in relationships ], []))) for group in known_groups: tags_groups.node('group-' + group, 'Group: ' + group) print "collating known targets" known_targets = list(set(sum([ [target['name'] for target in data['build_targets']] + [target['name'] for target in data['dest_targets']] for tag, data in relationships ], []))) for target in known_targets: tags_and_targets.node('target-' + target, 'Target: ' + target) print "building graph" for tag, data in relationships: for parent in data['parents']: tags_parent_child.edge(parent['name'], tag['name']) for group in data['group_list']: tags_groups.edge(tag['name'], 'group-' + group) for target in data['build_targets']: tags_and_targets.edge('target-' + target['name'], tag['name'], 'build') for target in data['dest_targets']: tags_and_targets.edge(tag['name'], 'target-' + target['name'], 'dest') print "writing" tags_parent_child.render() tags_groups.render() tags_and_targets.render() print "done"
Check out this first beast of a graph that it generates. It is a mapping of the parent/child inheritance relationship between tags (you can get at similar information with the $ koji list-tag-inheritance SOME_TAG command.
This next one shows koji tags and what 'targets' they have relationships with. There are two kind of relationships here. A target can be a "destination target" for a tag or it can be a "build target" for a tag.
Dennis Gilmore tells me that:
Targets are glue for builds. Targets define the tag used for the buildroot and the tag that the resulting build is tagged to.
Trying to unpack that -- take the rawhide target in this graph. It gets its buildroot definition from the f22-build tag, and builds that succeed there are sent to the f22 tag.

Anyways, the next step for my compose-in-staging project is to get that rawhide-repo-holder target setup. I think kojira will notice that and start building the appropriate rawhide/ repo for the next bits down the pipeline. Feel free to reuse and modify the graph-generating script above, it was fun to write, and I hope it's useful to you some day. Happy Hacking!
Datanommer database migrated to a new db host
Sep 29, 2014 | categories: fedmsg, datanommer, fedora View CommentsThe bad news: our database of all the fedmsg messages ever - it's getting slower and slower. If you use datagrepper to query it with any frequency, you will have noticed this. The dynamics of it are simple: we are always storing new messages in postgres and none of them ever get removed. We're over 13 million messages now.
When we first launched datagrepper for public queries, they took around 3-4s to complete. We called this acceptable, and even fast enough to build services that relied extensively on it like the releng dashboard. As things got slower, queries could take around 60s and pages like the releng dash that made 20 some queries to it would take a long time to render fully.
Three Possible Solutions
We started looking at ways out of this jam.
NoSQL -- funny, the initial implementation of datanommer written on top of mongodb and we are now re-considering it. At Flock 2014, yograterol gave a talk on NoSQL in Fedora Infra which has sparked off a series of email threads and an experiment by pingou to import the existing postgres data into mongo. The next step there is to run some comparison queries when we get time to see if one backend is superior to the other in respects that we care about.
Sharding -- another idea is to horizontally partition our giant messages table in postgres. We could have one hot_messages table that holds only the messages from the last week or month, another warm_messages table that holds messages from the last 6 months or so, and a third cold_messages table that holds the rest of the messages from time immemorial. In one version of this scheme, no messages are duplicated between the tables and we have a cronjob that periodically (daily?) moves messages from hot to warm and from warm to cold. This is likely to increase performance for most use cases, since most people are only ever interested in the latest data on topic X, Y or Z. If someone is interested in getting data from way back in time, they typically also have the time to sit around and wait for it. All of this, of course, would be an implementation detail hidden inside of the datagrepper and datanommer packages. End users would simply query for messages as they do now and the service would transparently query the correct tables under the hood.
PG Tools -- While looking into all of this, we found some postgres tools that might just help our problems short term (although we haven't actually gotten a chance to try them yet). pg_reorg and pg_repack look promising. When preparing to test other options, we pulled the datanommer snapshot down and imported it on a cloud node and found, surprisingly, that it was much faster than our production instance. We also haven't had time to investigate this, but my bet is that when it is importing data for the first time, postgres has all the time in the world to pack and store the data internally in a way that it knows how to optimally query. This needs more thought -- if simple postgres tools will solve our problem, then we'll save a lot more engineering time than if we try to rewrite everything against mongo or rewrite everything against a cascade of tables (sharding).
Meanwhile
Doom arrived.
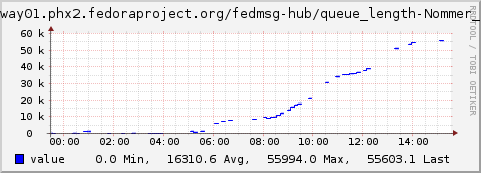
The above is a graph of the datanommer backlog from last week. The number on the chart represents how many messages have arrived in datanommer's local queue, but which have not been processed yet and inserted into the database. We want the number to be at 0 all the time -- indicating that messages are put into the database as soon as they arrive.
Last week, we hit an emergency scenario -- a critical point -- where datanommer couldn't store messages as fast as they were arriving.
Now.. what caused this? It wasn't that we were receiving messages at a higher than normal rate, it was that the database's slowness passed a critical point, the process of inserting a message was now taking too long, the rate at which we were processing messages was lower than necessary (see my other post on new measurements).
Migration
The rhel6 db host for datanommer was pegged so we decided to try and migrate it to a new rhel7 vm with more cpus as a first bet. This turned out to work much better than I expected.
Times for simple queries are down from 500 seconds to 4 seconds and our datanommer backlog graph is back down to zero.
The migration took longer than I expected and we have an unfortunate 2 hour gap in the datanommer history now. With some more forethought, we could get around this by standing up a temporary second db to store messages during the outage, and then adding those back to the main db afterwards. If we can get some spare cycles to set this up and try it out, maybe we can have it in place for next time.
For now, the situation seems to be under control but is not solved in the long run. If you have any interest in helping us with any of the three possible longer term solutions mentioned above (or have ideas about a fourth) please do join us in #fedora-apps on freenode and lend a hand.
Fedmsg Health Dashboard
Sep 29, 2014 | categories: fedmsg, fedora, collectd View CommentsWe've had collectd stats on fedmsg for some time now but it keeps getting better. You can see the new pieces starting to come together on this little fedmsg-health dashboard I put together.
The graphs on the right side -- the backlog -- we have had for a few months now. The graphs on the left and center indicate respectively how many messages were received by and how many messages were processed by a given daemon. The backlog graph on the right shows a sort of 'difference' between those two -- "how many messages are left in my local queue that need to be processed".
Having all these will help to diagnose the situation when our daemons start to become noticably clogged and delayed. "Did we just experience a surge of messages (i.e. a mass rebuild)? Or is our rate of handling messages slowing down for some reason (i.e., slow database)?"
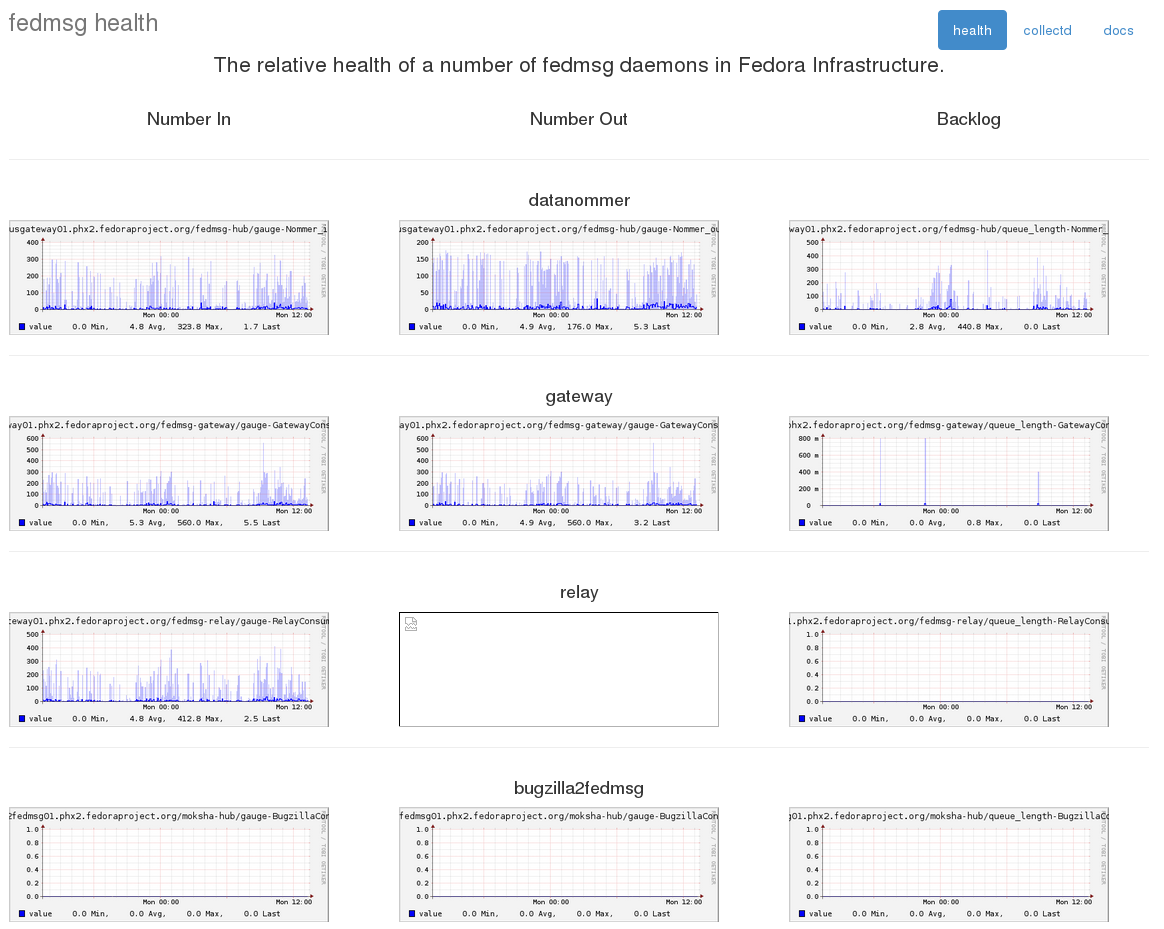
This is mostly for internal infrastructure team use -- but I thought it would be neat to share.
« Previous Page -- Next Page »
 [three]Bean.org
[three]Bean.org