[three]Bean
Fedmsg Health Dashboard
Sep 29, 2014 | categories: fedmsg, fedora, collectd View CommentsWe've had collectd stats on fedmsg for some time now but it keeps getting better. You can see the new pieces starting to come together on this little fedmsg-health dashboard I put together.
The graphs on the right side -- the backlog -- we have had for a few months now. The graphs on the left and center indicate respectively how many messages were received by and how many messages were processed by a given daemon. The backlog graph on the right shows a sort of 'difference' between those two -- "how many messages are left in my local queue that need to be processed".
Having all these will help to diagnose the situation when our daemons start to become noticably clogged and delayed. "Did we just experience a surge of messages (i.e. a mass rebuild)? Or is our rate of handling messages slowing down for some reason (i.e., slow database)?"
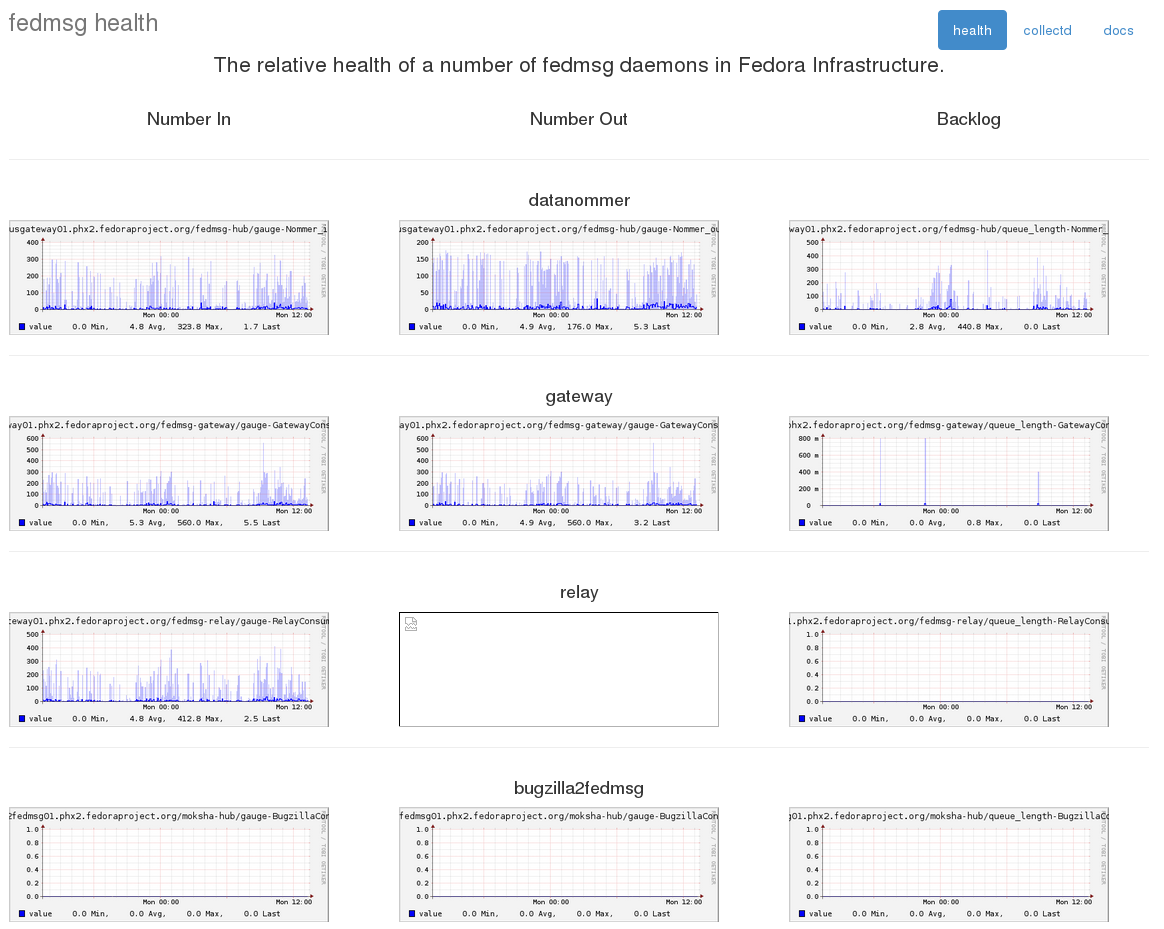
This is mostly for internal infrastructure team use -- but I thought it would be neat to share.
monitoring fedmsg process health in collectd
May 01, 2014 | categories: fedmsg, fedora, collectd View CommentsHappy May Day! Almost a year ago, we started monitoring fedmsg throughput in collectd.
Nowadays, we have many more message types on the bus and a much higher volume too. I started to get worried about the performance of the daemons handling messages. We have log files in /var/log/fedmsg/, but it required someone familiar to go and look at them. Too manual.
Well, over a month ago we cooked up an idea to expose more of the fedmsg-hub's internals for monitoring. That stuff has all been implemented and released after some sprint-work at PyCon. Janez Nemanič is working on nagios checks for all this and just yesterday I wrote the collectd plugin to pull all that information in for visualization. Take a look:
Here's the "backlog" of the Fedora Badges backend. It is a graph of how many messages have arrived in its internal queue, but that it has not yet dealt with. Smaller numbers are better here. As you can see, the badges awarder mostly stays on top of its workload. It can award badges almost as rapidly as it is notified of events.
Here is the same graph for summershum. It is a daemon that watches the bus, and when new source tarballs are uploaded to the lookaside cache, it downloads them, extracts the contents, and then computes and stores hashes of all the source files. The graph here has a different profile. Lookaside uploads occur relatively infrequently, but when they do occur summershum undertakes a significant workload:
Lastly, and this is my favorite, this is the backend for Fedora Notifications. It has some inefficiencies that need to be dealt with, which you can plainly see from the profile here. On some occasions, its backlog will grow to hundreds of messages.
For the curious, its workload looks like this: "when a message arrives, compare it against rules defined for every user in our database. If there are any matches, then forward that message on to that user." The inefficiencies stem almost entirely from database queries. For every message that arrives, it extracts every rule for every user from the database across the network. Unnecessary. We could cache all that in memory and have the backend then intelligently invalidate its own cache when a user changes a preference rule in the frontend. We could signal that such a change has been made with, you guessed it, a fedmsg message. Such a change is probably all that's needed...
...but now we have graphs. And with graphs we can measure how much improvement we do or don't get. Much nicer than guessing.
 [three]Bean.org
[three]Bean.org