[three]Bean
Threading Moksha
Mar 27, 2014 | categories: fedmsg, fedora, moksha View CommentsWe have this rad tool in Fedora Infrastructure we use for passing around server-side messages called fedmsg. It uses zeromq behind the scenes and it is built on top of a framework Luke Macken made called Moksha (which is in turn built on top of Twisted).
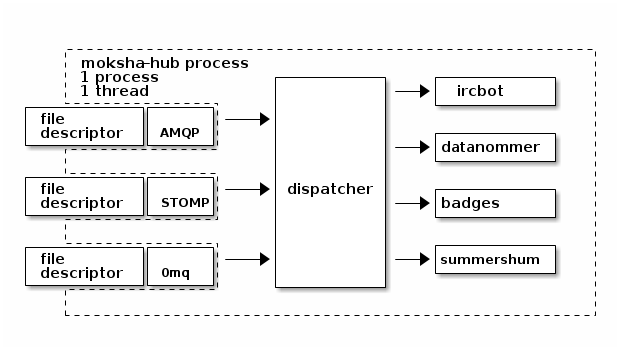
To cut to the chase, I have a problem where I want to be able to measure how backlogged some of our message processing consumers are. Here's a diagram of how moksha works as things stand now:
Furthermore, here's a depiction of Twisted's own event loop; all of Moksha's code that I'll be discussing lives below in the "our code" section:

Now, when a message arrives, it is picked up by one of the backends (in our case, the zeromq one) and that message is handed of to the moksha dispatcher ("our code"). The dispatcher then hands that message to any locally registered message consumers that might want it, one after another in series (a consumer is just a Python class that defines a .consume(self, message) method). Some of these message consumers are quite fast: the datanommer consumer just stuffs the message in a postgres database for later analysis. The ircbot consumer just formats the message and sends it off to freenode (although, it throttles itself so as to not get kicked for being spammy). Other consumers take a longer time to handle individual messages. The Fedora Badges message consumer has to compare the message against a couple hundred different rules and some of those rules involve making large database queries -- not quick. The Fedora Notifications consumer has to compare the message against as many different rules and then ultimately forward the message on to irc, email or google cloud messaging for android -- not quick.
At the time of this writing, we have 2,752,890 messages in our message store which has been operating since October 2012. That averages about 4 messages per minute (quite low), but we often have relatively large spikes in volume, around 120 messages per second. How much does that backlog our consumer processes? How long does it take them to catch up? We can eyeball the logs and make guesses, but I'd really like to measure and track it.
Here's an idea. We split the moksha dispatcher into a main "enqueuing" thread and a secondary "dispatching" thread.
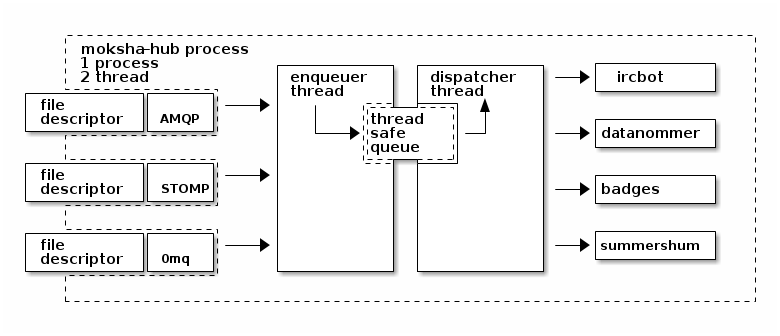
The logic for the enqueuer is simple: "when a message arrives, put it on the work queue". The logic for the new secondary dispatcher thread is also simple: "when I find a message in the queue, hand it off to each of my registered consumers in serial". Only when the last consumer has finished a message does the dispatcher thread then return to its work queue to get the next message. The dispatcher thread works much like it did before, but we introduce a little buffer in front of it that we can measure (with collectd, in our case).
Perhaps we can take it further. Give each consumer its own thread and work queue so they can work in parallel:
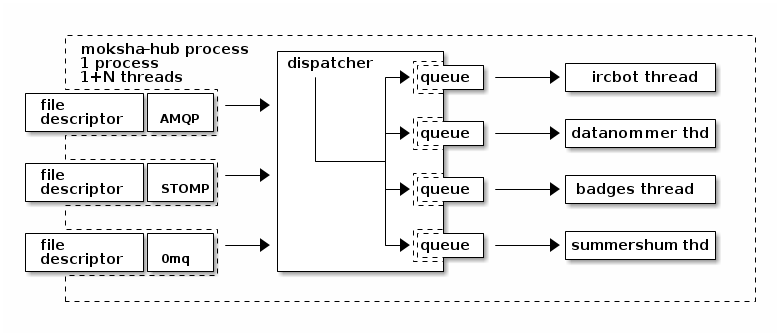
Here, the enqueuer changes: "when a message arrives, put it in each consumer queue that is registered for this kind of message." Each consumer now is managed by its own thread which picks its own messages off of its own queue and handles them as they can. The advantage here is that we can measure just how backlogged each particular consumer becomes, not just the whole hub.
Things might get tricky as some consumers might have been hacked together to share state that they shouldn't be -- I know the notifications backend does some silly stuff sharing access to the irc connection between consumers. That can be dealt with, though.
So, I dunno, good idea? Bad idea? Lemme know in #fedora-apps or #moksha on freenode.
 [three]Bean.org
[three]Bean.org