[three]Bean
Rube → Selenium tests for Fedora Infrastructure
Mar 25, 2013 | categories: rube, infrastructure, selenium, fedora View CommentsSometime last week, we updated all the packages in our staging environment. Our theory goes: we do it in staging first; if it works, then do it in production. After executing that update, we let it sit for a few hours and then asked: "Is everything working?" Well, nothing fell down (that we could see).
Since fedmsg has come online, we know from watching the #fedora-fedmsg irc logs that practically noone uses the staging environment for anything. On a hunch, I went and tried to flex a few features of our webapps: a little of this, a little of that. I tried logging into the wiki and boom: a 500 error.
So, that's a problem.
In response, I wrote Rube which uses selenium to open up Firefox and run ~30 automated tests against our services in staging. That's a good thing. For you, it means the infrastructure team won't break stuff you use as often. For us, it means we can stress out less and spend more time making more awesome.
Big thanks to lmacken, decause and relrod who contributed code and energy. It can still use more tests cases, so if you have one in mind please contribute!
Live visualization of fedmsg activity
Mar 04, 2013 | categories: python, fedmsg, zeromq, fedora, gource View CommentsAnother crazy idea -- piping ØMQ into gource!
If you have problems with the video, you can download it directly here in ogg or webm.
As before, I used gravatar.com to grab
the avatar images, using the FAS_USERNAME@fedoraproject.org
formula.
Props to decause for the idea.
Fedmsg Reliability -- No More Dropped Messages?
Feb 28, 2013 | categories: fedmsg, zeromq, fedora View CommentsQuick Timeline:
- February, 2012 - I started thinking about fedmsg.
- March, 2012 - Development gets under way.
- July, 2012 - Stuff gets working in staging.
- August-September, 2012 - The first messages hit production. We notice that some messages are getting dropped. We chalk it up to programming/configuration oversights. We are correct about that in some cases.
- October-November, 2012 - Some messages are still getting dropped. Theory develops that it is due to zeromq2's lack of TCP_KEEPALIVE. It takes time to package zeromq3 and test this, integrate it with Twisted bindings, and deploy. More message sources come online during this period. Other stuff like externally consuming messages [1] [2], datanommer [3] [4], and identica [5] happen too.
- January, 2013 - I enabled the TCP_KEEPALIVE bits in production at FUDCon Lawrence.
I haven't noticed any dropped messages since then: a marked improvement. However, our volume of messages is so much higher now that it is difficult to eyeball. If you notice dropped messages, please let me know in #fedora-apps on freenode.
Async Caching & the Fedora Packages App
Feb 07, 2013 | categories: python, cache, ruby, fedora View CommentsBackstory
Luke (lmacken) Macken, John (J5) Palmieri, and Máirín (mizmo/miami) Duffy created the Fedora Packages webapp; its initial release was about this time last year at FUDCon Blacksburg. It is cool!
Over the summer, I wrote a python api and cli tool called pkgwat to query it. David Davis then wrote his own ruby bindings which now power the Is It Fedora Ruby? webapp.
In late 2012 as part of another scheme, I redirected the popular https://bugz.fedoraproject.org/$SOME_PACKAGE alias from an older app to the packages app's bug list interface.
There was a problem though: developers reported that the page didn't work and was too slow!
Darn.
Caching
There were a number of small bugs (including an ssl timeout when querying Red Hat's bugzilla instance). Once those were cleared there remained the latency issue. For packages like the kernel, our shiny webapp absolutely crawled; it would sometimes take a minute and a half for the AJAX requests to complete. We were confused -- caching had been written into the app from day one, so.. what gives?
To my surprise, I found that our app servers were being blocked from talking to our memcached servers by iptables (I'm not sure how we missed that one). Having flipped that bit, there was somewhat of an improvement, but.. we could do better.
Caching with dogpile.cache
I had read Mike Bayer's post on dogpile.cache back in Spring 2012. We had been using Beaker, so I decided to try it out. It worked! It was cool...
...and I was completely mistaken about what it did. Here is what it actually does:
- When a request for a cache item comes in and that item doesn't exist, it blocks while generating that value.
- If a second request for the same item comes in before the value has finished generating, the second request blocks and simply waits for the first request's value.
- Once the value is finished generating, it is stuffed in the cache and both the first and second threads/procs return the value "simultaneously".
- Subsequent requests for the item happily return the cached value.
- Once the expiration passes, the value remains in the cache but is now considered "stale".
- The next request will behaves the same as the very first: it will block while regenerating the value for the cache.
- Other requests that come in while the cache is being refreshed now do not block, but happily return the stale value. This is awesome. When a value becomes stale, only one thread/proc is elected to refresh the cache, all others return snappily (happily).
The above is what dogpile.cache actually does (to the best of my story-telling abilities).
In my imagination, I thought that step number vi didn't actually block. I thought that dogpile.cache would spin off a background thread to refresh the cache asynchronously and that number vi's request would return immediately. This would mean that once cache entries had been filled, the app would feel quick and responsive forever!
It did not work that way, so I submitted a patch. Now it does. :)
Threads
A programmer had a problem. He thought to himself, "I know, I'll solve it with threads!". has Now problems. two he
With dogpile.cache now behaving magically and the Fedora Packages webapp patched to take advantage of it, I deployed a new release to staging the day before FUDCon and then again to production at FUDCon on Saturday, January 19th, 2013. At this point our memcached servers promptly lost their minds.
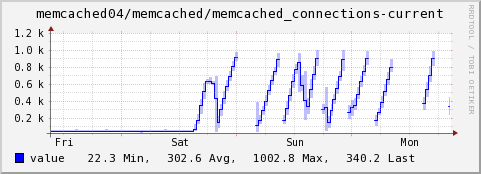
Mike Bayer sagely warned that the approach was creepy.
Each of those threads weren't cleaning up their memcached connections properly and enough were being created that the number of concurrent connections was bringing down the cache daemon. To make it all worse, enough changes were made rapidly enough at FUDCon that isolating what caused this took some time. Other environment-wide FUDCon changes to my fedmsg system were also causing unrelated issues and I spent the following week putting out all kinds of fires in all kinds of contexts in what seemed like a never-ending rush. (New ones were started in the process too, like unearthing a PyCurl issue in python-fedora, porting the underlying mechanism to python-requests, only to encounter bundling, compatibility, and security bugs there.)
A long-running queue
During that rush, I reimplemented my async_creator.
Where before it would start up a new thread, do the work, update the cache, and release the mutex, now it would simply drop a note in a redis queue with python-retask. With that came a corresponding worker daemon that picks those tasks off the queue one at a time, does the work, refreshes the cache and releases the distributed dogpile lock before moving on to the next item.
The app seems to be working well now. Any issues? Please file them if so. I am going to take a nap.
Where does the "wat" come from in "pkgwat"?
Jan 22, 2013 | categories: pkgwat, wat, fedora View CommentsI was surprised to learn that lots of folks didn't know where the "wat" came from in the name of my "pkgwat" project.
...it comes from this amazing lightning talk.
« Previous Page -- Next Page »
 [three]Bean.org
[three]Bean.org