[three]Bean
PyCon 2015 (Part I)
Apr 12, 2015 | categories: python, fedora, pycon View CommentsA few of us from Fedora are at PyCon US in Montreal for the week. The conference portion is almost over and the sprints start tomorrow, but in the meantime here are some highlights from the best sessions I sat in on:
- @nnja gave a great talk on technical debt and how it can contribute to a "culture of despair".
- @sigmavirus24's talk on writing tests against python-requests was supremely useful. Using his material, I wrote a patch for anitya that solved an onerous and recurring issue with the test suite.
- You've just got to see this talk on pypy.js. In short, he used llvm to compile pypy into javascript so it can run in the browser (with asm.js) which runs faster than CPython, amazingly.
- Raymond Hettlinger gave a very nice talk on "moving beyond pep8" which was pretty relevant for my team and our code review practices. We write a lot of code which entails doing a lot of code review. His thesis: working in a cosmetic pep8 mindset causes you to often miss the elephant in the room when doing code review. Instructive.
- There was a very good talk on one particular company's experiences with a microservices architecture. It is of special interest to me and our work on the Fedora Infrastructure team with lots of good take-aways. The video of it hasn't been posted yet, but definitely search for it in the coming days.
- I quite disagreed with some of the method presented in the effective python session. No need for wrapper-class boilerplate -- just use itertools.tee(...)!
- Some others: distributed systems theory, interpreting your genome, systems stuff for non-systems people, and ansible were all very nice.
Some hacking happened in the interstitial periods!
- I wrote a prototype of a system to calculate and store statistics about fedmsg activity and some plugins for it. This will hopefully turn out to be quite useful for building community dashboards in the future (like a revamped releng dashboard or the nascent fedora-hubs).
- We ported python-fedora to python3! Hooray!
- The GSOC deadline really snuck up on us, so Pierre-Yves Chibon and I carved out some time to sit down and go over all the pending applications.
I'm really looking forwards to the sprints and the chance to work and connect with all our upstreams. We'll be holding a "Live From Pycon" video cast at some point. Details forthcoming. Happy Hacking!
Fedora Photowall
Sep 04, 2014 | categories: python, fedora View CommentsIf you didn't already know it, there is a Fedora Badge for associating a libravatar with your Fedora account.

A fun by-product of having such a thing is that we have a list of FAS usernames of people who have public avatars with predictable URLs. With that, I wrote a script that pulls down that list and assembles a "photo wall" of a random subset. Check it out:

I wrote it as a part of another project that I ended up junking, but the script is neat on its own.
Perhaps we can use it as a splash image for a Fedora website someday (say, next year's Flock site or a future iteration of FAS?). It might make a fun desktop wallpaper, too.
Here's the script if you'd like to re-use and modify. You can tweak the dimensions variable to change the number of rows and columns in the output.
#!/usr/bin/env python """ fedora-photowall.py - Make a photo montage of Fedora contributors. Dependencies: $ sudo yum install python-sh python-beautifulsoup4 python-requests ImageMagick Usage: python fedora-photowall.py Author: Ralph Bean License: LGPLv2+ """ import hashlib import os import random import urllib import sh import bs4 import requests dimensions = (12, 5) datadir = './data' avatar_dir = datadir + '/avatars' montage_dir = datadir + '/montage' def make_directories(): try: os.makedirs(datadir) except OSError: pass try: os.makedirs(avatar_dir) except OSError: pass try: os.makedirs(montage_dir) except OSError: pass def avatars(N): url = 'https://badges.fedoraproject.org/badge/mugshot/full' response = requests.get(url) soup = bs4.BeautifulSoup(response.text) last_pane = soup.findAll(attrs={'class': 'grid-100'})[-1] persons = last_pane.findAll('a') persons = random.sample(persons, N) for person in persons: name = person.text.strip() openid = 'http://%s.id.fedoraproject.org/' % name hash = hashlib.sha256(openid).hexdigest() url = "https://seccdn.libravatar.org/avatar/%s" % hash yield (name, url) def make_montage(candidates): """ Pull down avatars to disk and stich with imagemagick """ filenames = [] for name, url in candidates: filename = os.path.join(avatar_dir, name) if not os.path.exists(filename): print "Grabbing", name, "at", url urllib.urlretrieve(url, filename=filename) else: print "Already have", name, "at", filename filenames.append(filename) args = filenames + [montage_dir + '/montage.png'] sh.montage('-tile', '%ix%i' % dimensions, '-geometry', '+0+0', *args) print "Output in", montage_dir def main(): make_directories() N = dimensions[0] * dimensions[1] candidates = avatars(N) make_montage(candidates) if __name__ == '__main__': main()
And another example of output:
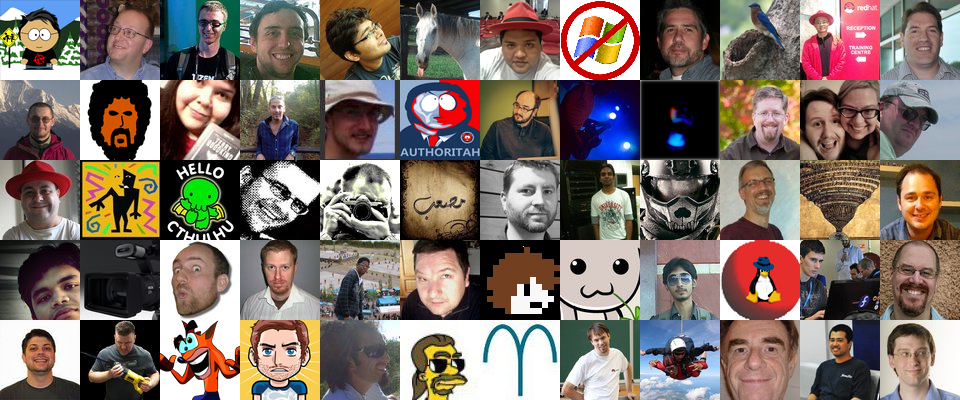
Cheers!
A tiny optimization
Sep 03, 2013 | categories: python, nitpicking, fedora View CommentsTalking over a pull request with @pypingou, we found that this one method of constructing a set from a list of stripped strings was slightly faster than another:
#!/usr/bin/env python """ Timing stuff. :: $ python timeittest.py set(map(str.strip, ['wat '] * 200)) 30.9805839062 set([s.strip() for s in ['wat '] * 200]) 31.884624958 """ import timeit def measure(stmt): print stmt results = timeit.timeit(stmt) print results measure("set(map(str.strip, ['wat '] * 200))") measure("set([s.strip() for s in ['wat '] * 200])")
Admission: Pierre bullied me into blogging about this!
UPDATE: Folks in the comments recommended using a generator or itertools.imap. The results are significantly better. Here they are:
import itertools; [s.strip() for s in ['wat '] * 200] 28.2224271297 import itertools; (s.strip() for s in ['wat '] * 200) 3.0280148983 import itertools; map(str.strip, ['wat '] * 200) 25.7294211388 import itertools; itertools.imap(str.strip, ['wat '] * 200) 2.3925549984
UPDATE (again): Comments further reveal that the update above is misleading -- the generators aren't actually doing any work there. If we force them to spin out, we get results like these:
import itertools; set([s.strip() for s in ['wat '] * 200]) 33.4951019287 import itertools; set((s.strip() for s in ['wat '] * 200)) 35.5591659546 import itertools; set(map(str.strip, ['wat '] * 200)) 33.7568879128 import itertools; set(itertools.imap(str.strip, ['wat '] * 200)) 35.9931280613
No clear benefit for use of imap or generators.
Distributing jobs via hashmaths
Jun 10, 2013 | categories: python, aosa, fedmsg, fedora View CommentsAs things stand, we can't load balance across multiple fedmsg-hub daemons (We can and do balance across multiple fedmsg-gateway instances, though -- that is another story).
For the hubs though, here's a scheme that might work. However.. is it fast enough?
#!/usr/bin/env python """ Distribute jobs via.. "hashspace"? Actually give this a run. See what it does. I learned about it from the mailman3 chapter in AOSA http://www.aosabook.org/en/mailman.html """ import json import hashlib class Consumer(object): def __init__(self, i, n): self.i = i self.n = n def should_I_process_this(self, msg): """ True if this message falls in "our" portion of the hash space. This seems great, except I bet its pretty expensive. Can you come up with an equivalent, "good enough" method that is more efficient? """ as_a_string = json.dumps(msg) as_a_hash = hashlib.md5(as_a_string).hexdigest() as_a_long = int(as_a_hash, 16) return (as_a_long % self.n) == self.i def demonstration(msg): """ Handy printing utility to show the results """ print "* Who takes this message? %r" % msg for consumer in consumers: print " *", consumer.i, "of", consumer.n, "hubs.", print " Process this one?", consumer.should_I_process_this(msg) if __name__ == '__main__': # Say we have 4 moksha-hubs each running the same set of consumers. # For story-telling sake, we'll say we're dealing here with the datanommer # consumer. Let's pretend it has to do some heavy scrubbing on the message # before it throws it in the DB, so we need to load-balance that. # As things stand now with fedmsg.. we can't do that *hand waving*. # This is a potential scheme to make it possible. # We have 4 moksha-hubs, one on each of 4 machines. N = 4 consumers = [Consumer(i, N) for i in range(N)] # Fedmsg delivers a message. All 4 of our hubs receive it. # They each take the md5 sum of the message, convert that to a long # and then mod that by the number of moksha-hubs. If that remainder is # *their* id, then they claim the message and process it. demonstration(msg={'blah': 'I am a message, lol.'}) demonstration(msg={'blah': 'I am a different message.'}) demonstration(msg={'blah': 'me too.'}) # Since md5 sums are "effectively" random, this should distribute across # all our nodes mostly-evenly.
As I was typing this post up, Toshio Kuratomi mentioned that I should look into zlib.adler32 and binascii.crc32 if I am concerned about speed (which I am).
Perhaps some benchmarking is in order?
ToscaWidgets2 Sprint Postponed
Jun 04, 2013 | categories: python, tw2 View CommentsLast week, Moritz Schlarb announced a tw2 sprint set for this coming weekend.
Unfortunately, we discovered in #toscawidgets that we need to reschedule. The new dates are tentatively set for August 26th - 28th, 2013.
If you have any items you want us to take up or you'd like to participate, please see our laundry list.
« Previous Page -- Next Page »
 [three]Bean.org
[three]Bean.org